An interesting problem to solve in OpenStack is the management of OpenStack’s services. Whether it’s at the time of provisioning or updating, the OpenStack services could listen on similar ports and require modification of common configuration files.
Because of this, the services could potentially conflict with one another if deployed on the same system. For example, the network service may attempt to listen on the same port as the identity service or the compute service may edit a file that the network service expects to have different values. How do you deal with this problem, particularly when each OpenStack project has a tendency to work as an independent project? It doesn’t seem likely that it would be easy to drive consensus between the various projects on ports to listen on, configuration files to modify – particularly with the speed that OpenStack is moving.
For example, let’s suppose that one wants to deploy a network service. Assuming they are using a build based (sometimes referred to as package based) deployment method they might perform something similar to the following.


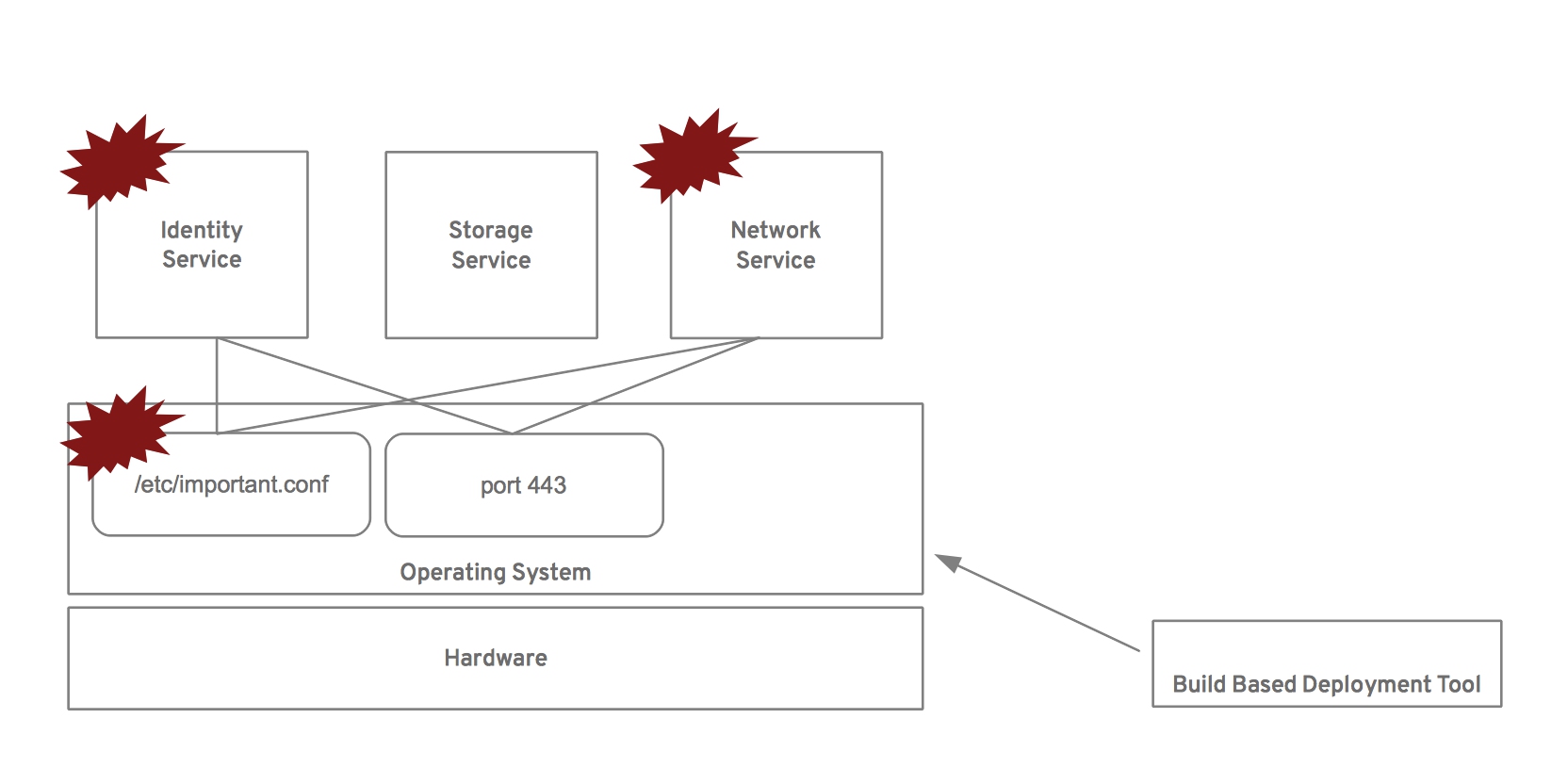
The result is a non-working network service and the potential for a non-working identity service if it is ever restarted. This problem is also found in image based deployment, it’s simply found earlier in the workflow, during the image generation phase. After all, the images that are being deployed need to be generated in the first place. The fundamental problem is that understanding what services are deployed on a particular host and resolving the dependencies or making necessary changes is not something the package or image generation tools understand.
One possible solution is to place each service on it’s own unique piece of hardware. This solves the problem of conflicts between the services configuration, but is not optimal as the overhead of the OpenStack services would not justify it’s own physical system until a particular scale is reached. Even then, locating the services close to compute nodes would also inhibit providing each service it’s own dedicated piece of hardware.
Another possible solution is to build into the tools, the logic and understanding of the OpenStack services and their configuration. While this sounds like a small task – it is not. The possible combinations of services that could be combined on a single host does not lend itself to easily creating let alone maintaining this logic.
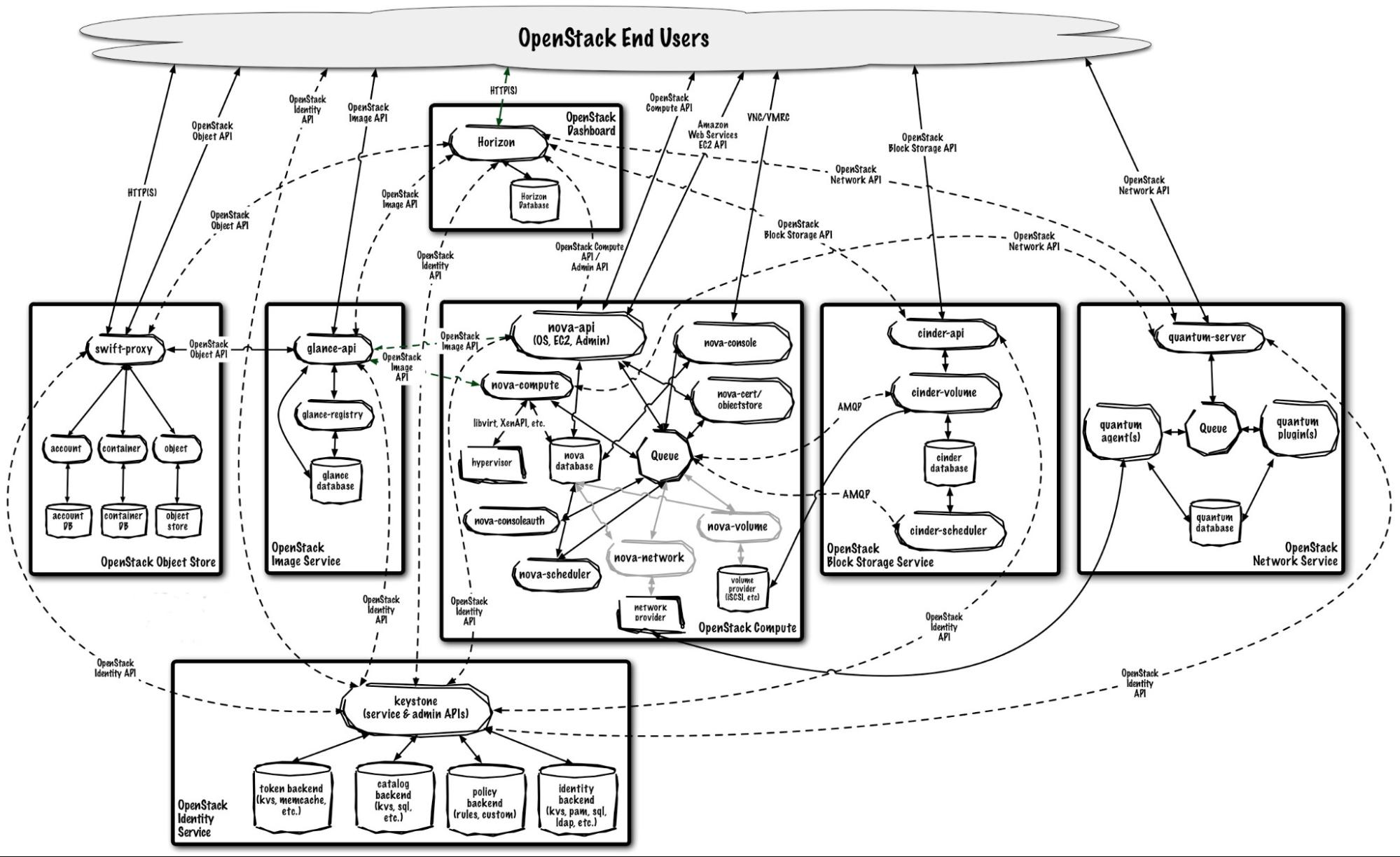
OpenStack Architecture
Yet another possible solution is to utilize virtual machines. This solves the hardware problem and provides isolation, but it has some disadvantages. Virtual machines are heavyweight. Whether it’s building new virtual machine images because of a simple update or installing the configuration infrastructure necessary to update virtual machines (and the overhead of start/stop operations, less rich interfaces for metadata, etc) virtual machines are not ideal.
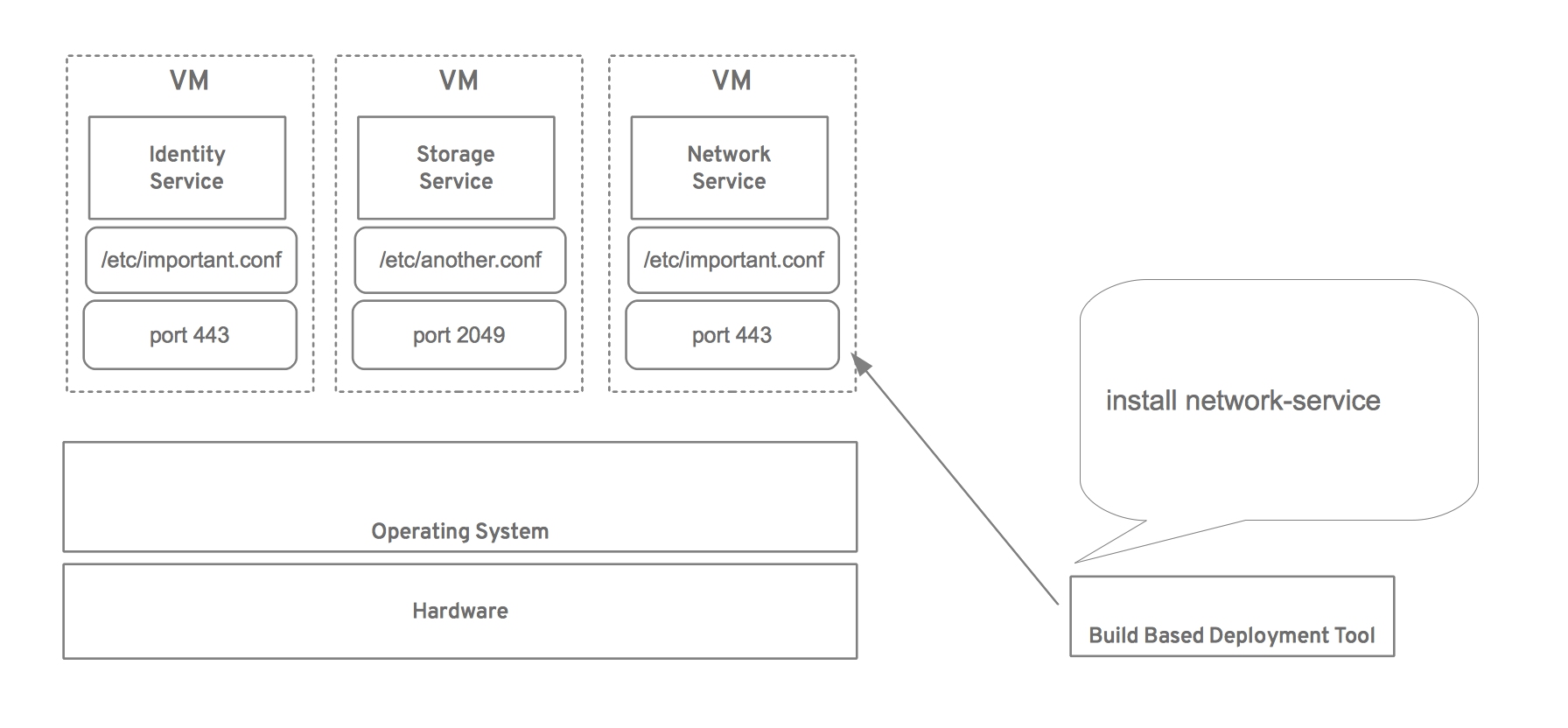


It may be possible to use Linux containers to solve this problem. Linux containers offer a lightweight virtualization that provide (among other things) process and network isolation. The isolation provided by containers means that tools such as a build based or image based deployment tools don’t need to maintain the logic of how the services on hosts could be deployed or updated without effecting one another.

I hope to provide more information soon on how projects like systemd might provide a mechanism for solving dependencies between OpenStack services running in containers – maybe even using Docker. Also, how ostree might lend a hand in some of the troubles of package management too.

This has been on my mind for over a year what would a Docker-like container set up for cloud services look like.
And I’ve not had as much time to devote on it as I wanted to.
I think containers work for most of the OpenStack services. There are exceptions where it doesn’t make as much sense like on the Hypervisor node and I wonder if it makes sense for something like a L3 router.
And there are things where it probably can’t work, like Nova Baremetal/Ironic.
You can’t connect to an an iSCSI-target because I don’t think you can create any new devices from with in the container.