In order to deliver services faster to their customers organizations need to ensure their development and operations teams work in unison. Over the last weeks and months I’ve been fortunate enough to spend time with several organizations in industries ranging from telecommunications, to financial services, to transportation to gain a better understanding of how they are allowing their development and operations teams to work more smoothly together and to observe where they are struggling. In this post I’ll attempt to summarize the common approaches and articulate the opportunity for improving service design.
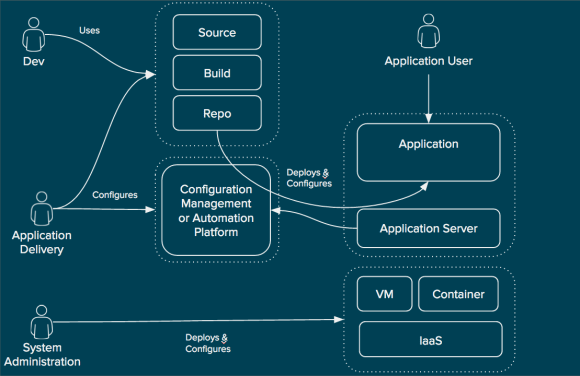
Prior to explaining the common approaches that development and operations teams have implemented or plan to implement let’s examine two common ways development and operations work together when it comes to repeatability.
Using Repeatable Deployments
In this approach, a member of the development team (sometimes a developer, but often a system administrator within the development team itself) makes a request for a given service. This service may require approvals and fall under some type of governance, but it is automatically instantiated. Details about the service are then delivered back to the requester. The requester then controls the lifecycle of everything within the service, such as updating and configuring the application server and deploying the application itself.
Using Repeatable Builds
In this approach, a member of the development team (most often a developer) requests a given service. This service is automatically deployed and the requester is provided an endpoint in which to interact with the service and an endpoint (usually a source control system) to use for modification of the service. The requester is able to modify certain aspects of the service (most often the application code itself) and these modifications are automatically propagated to the instantiated service.
There are several patterns that I have observed with regards to the implementation of repeatability.
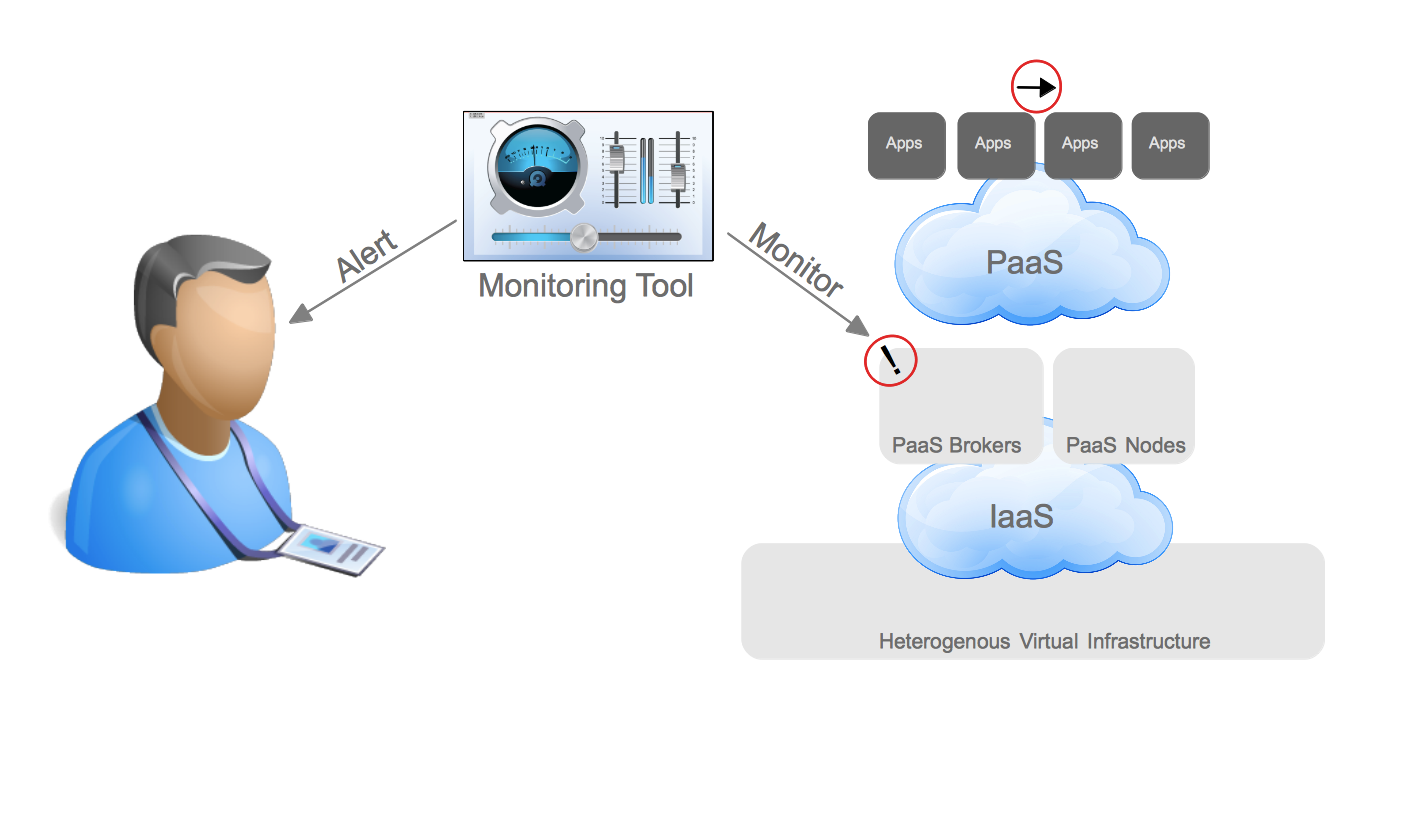
Repeatable Deployment
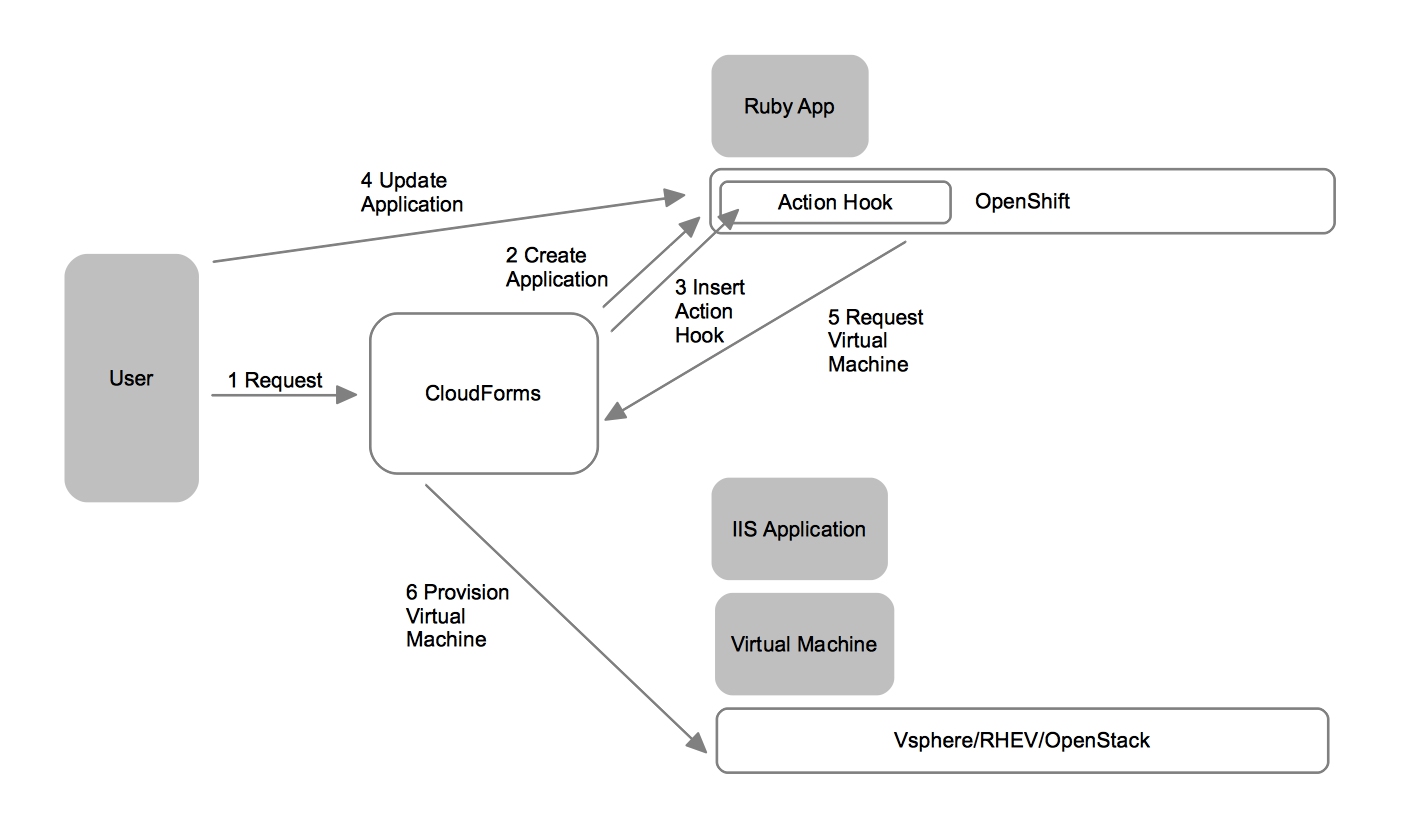
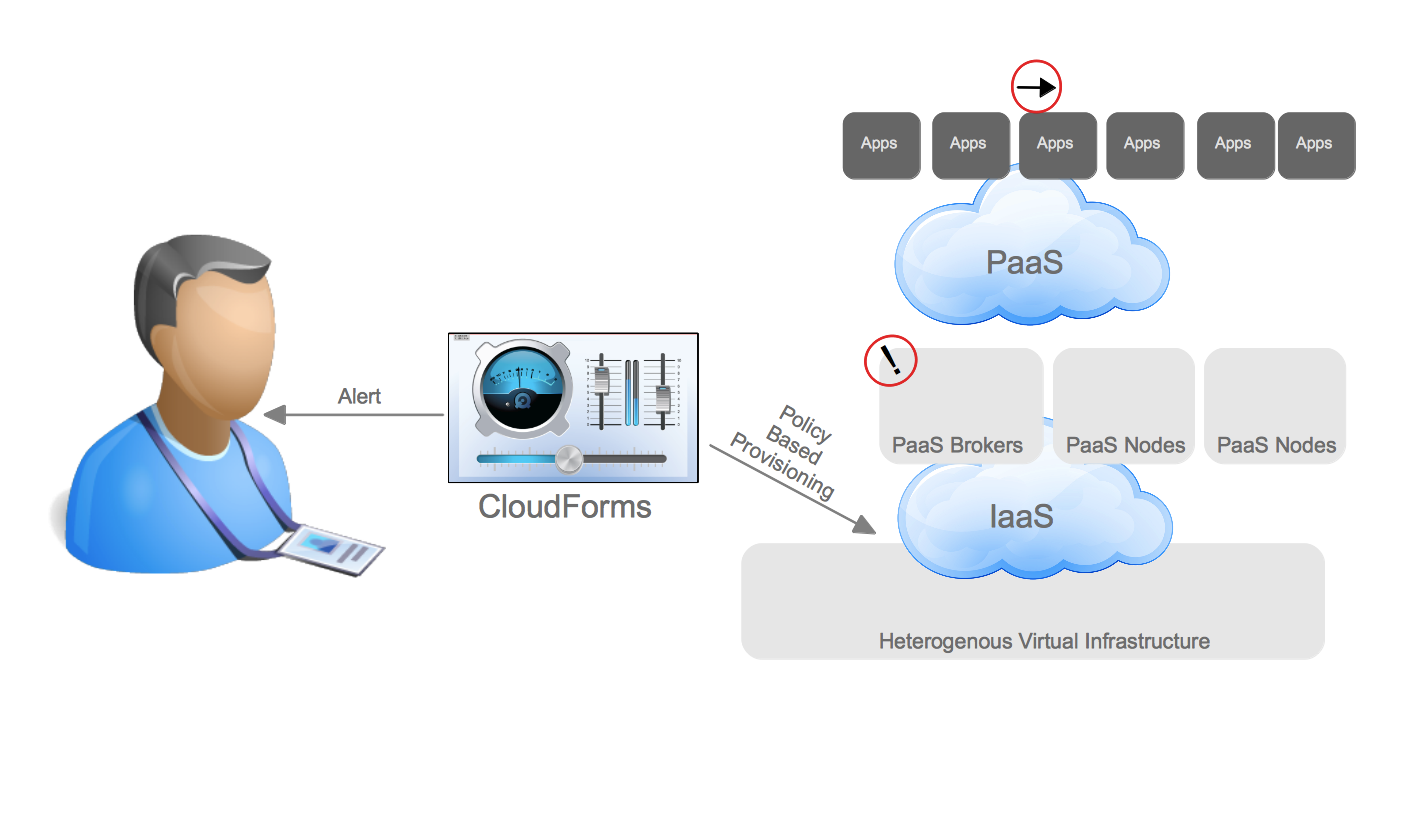
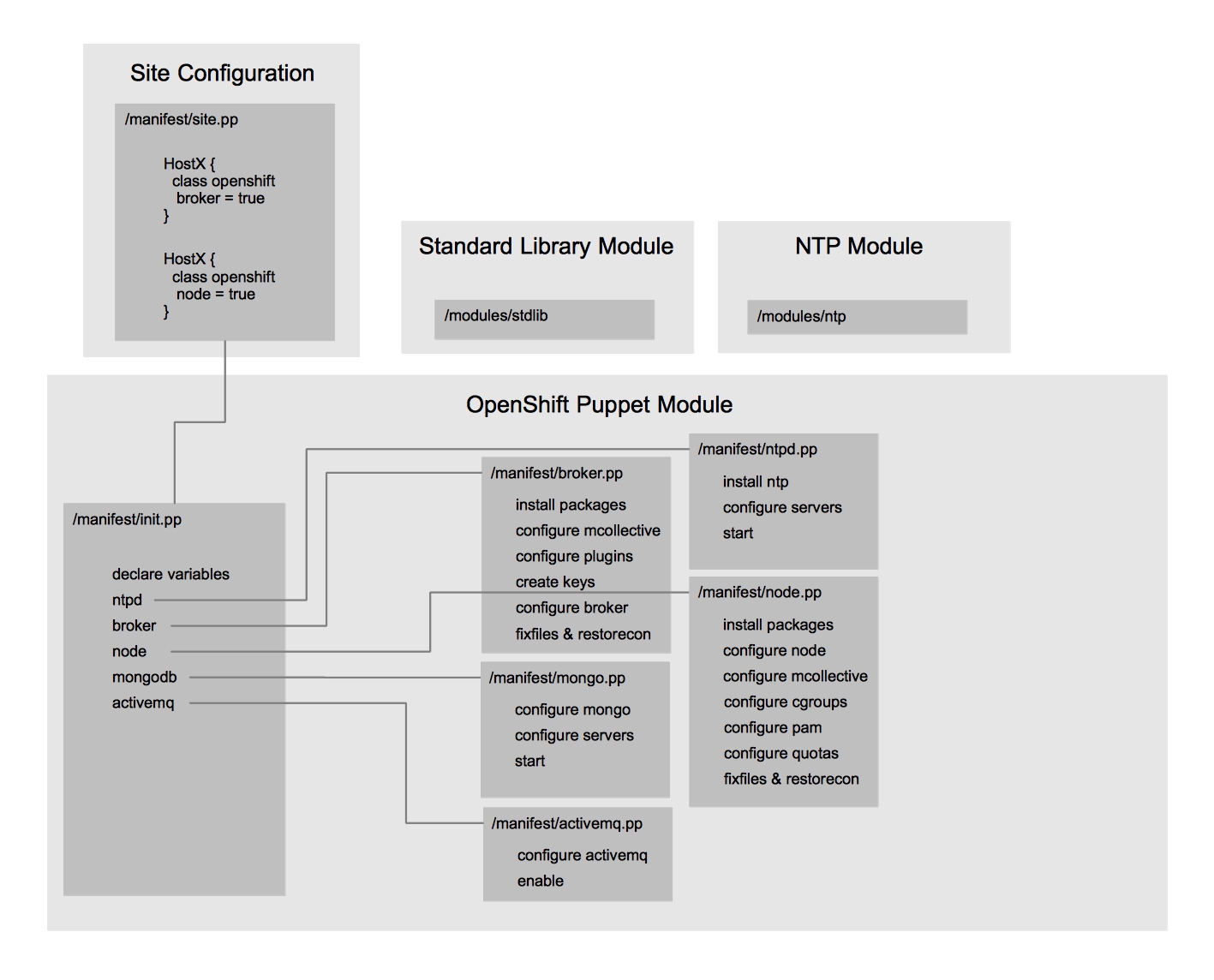
First is what I call “Repeatable Deployment”. It is probably familiar to anyone who has been in IT for the last 20 years. System administration teams deploy and configure the infrastructure components. This includes provisioning of the virtual infrastructure, such as virtual switches, storage, and machines and installing the operating system (or using a golden image). When it comes to containers, the system administration teams believe they will also provision the container and secure it in the low automation scenario.
Repeatable Deployments (High Level)
Once the infrastructure has been configured it is handed over to the application delivery teams. These teams deploy the necessary application servers to support the application that will run. This often includes application server clustering configuration and setting database connection pool information. These are things that developers and system administrators don’t necessarily know or care about. Finally, the application is deployed from a binary that is in a repository. This can be a vendor supplied binary or something that came from a build system that the development team created.
What is most often automated in this pattern is the deployment of the infrastructure and sometimes the deployment and configuration of the application server. The deployment of the binary is not often automated and the source to image process is altogether separated from the repeatable deployment of the infrastructure and application server.
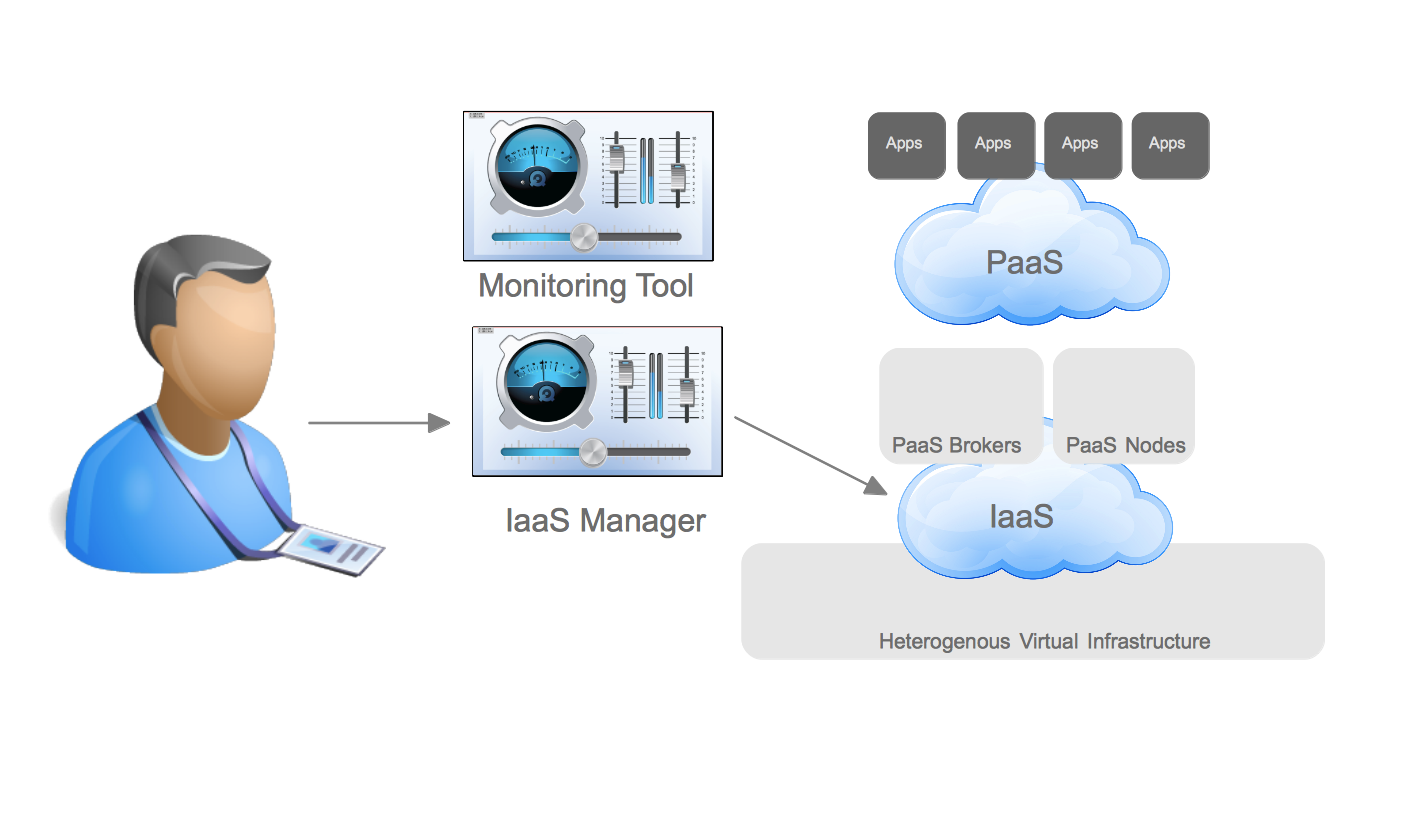
Custom Repeatable Build
Next is what I call “Custom Repeatable Build”. This pattern is common in organizations that began automating prior to the emergence of prescriptive methods of automation or because they had other reasons like flexibility or expertise that they wanted to leverage.
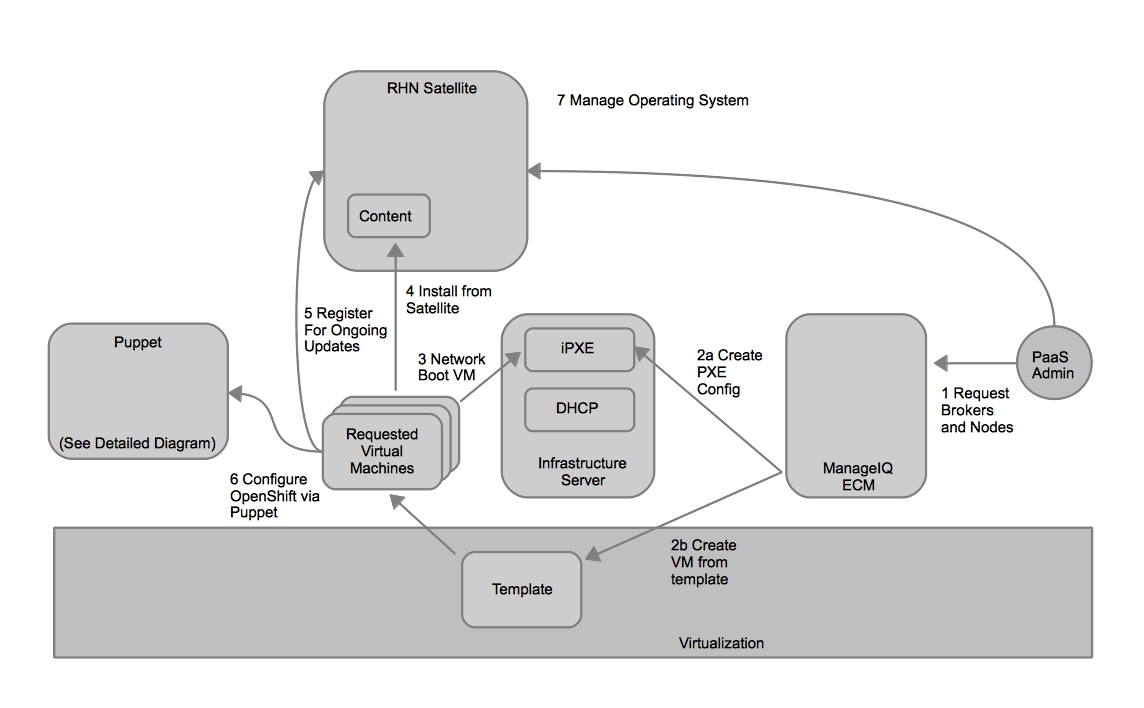
In this pattern system administration teams are still responsible for deploying and configuring the infrastructure including storage, network, and compute as a virtual machine or container. This is often automated using popular tools. This infrastructure is then handed over as an available “unit” for the application delivery teams.
The application delivery teams in this pattern have taken ownership of the process of taking source to image and configuring the application server and delivering binary to the application server. This is done through the use of a configuration management or automation platform.
This pattern greatly decreases the time it takes to move code from development to operational. However, the knowledge required to create the source to image process and automate the deployment is high. As more application development teams are onboarded the resulting complexity also greatly increases. In one instance it took over 3 months to onboard a single application into this pattern. In a large environment with thousands of applications this would be untenable.
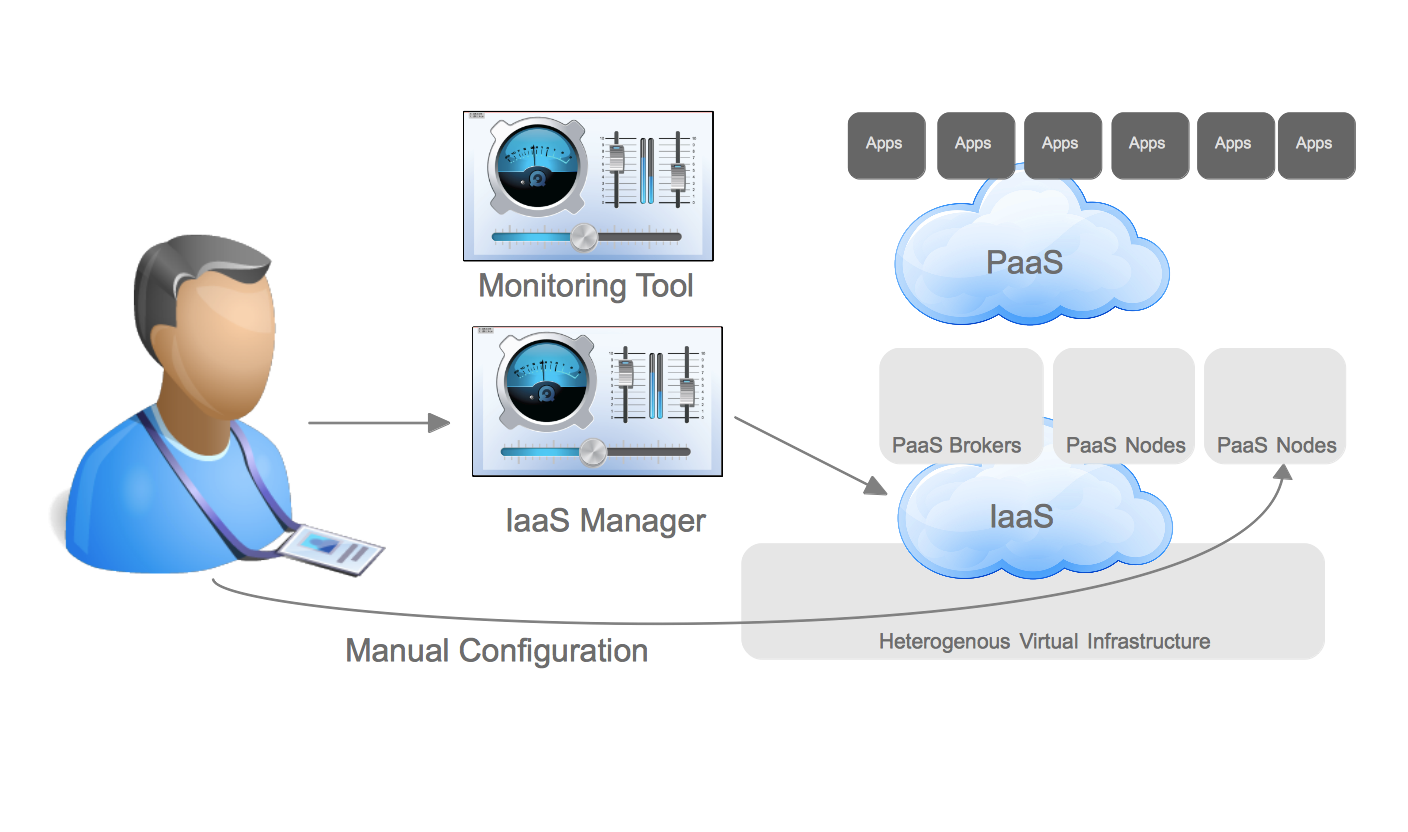
Prescriptive Repeatable Build
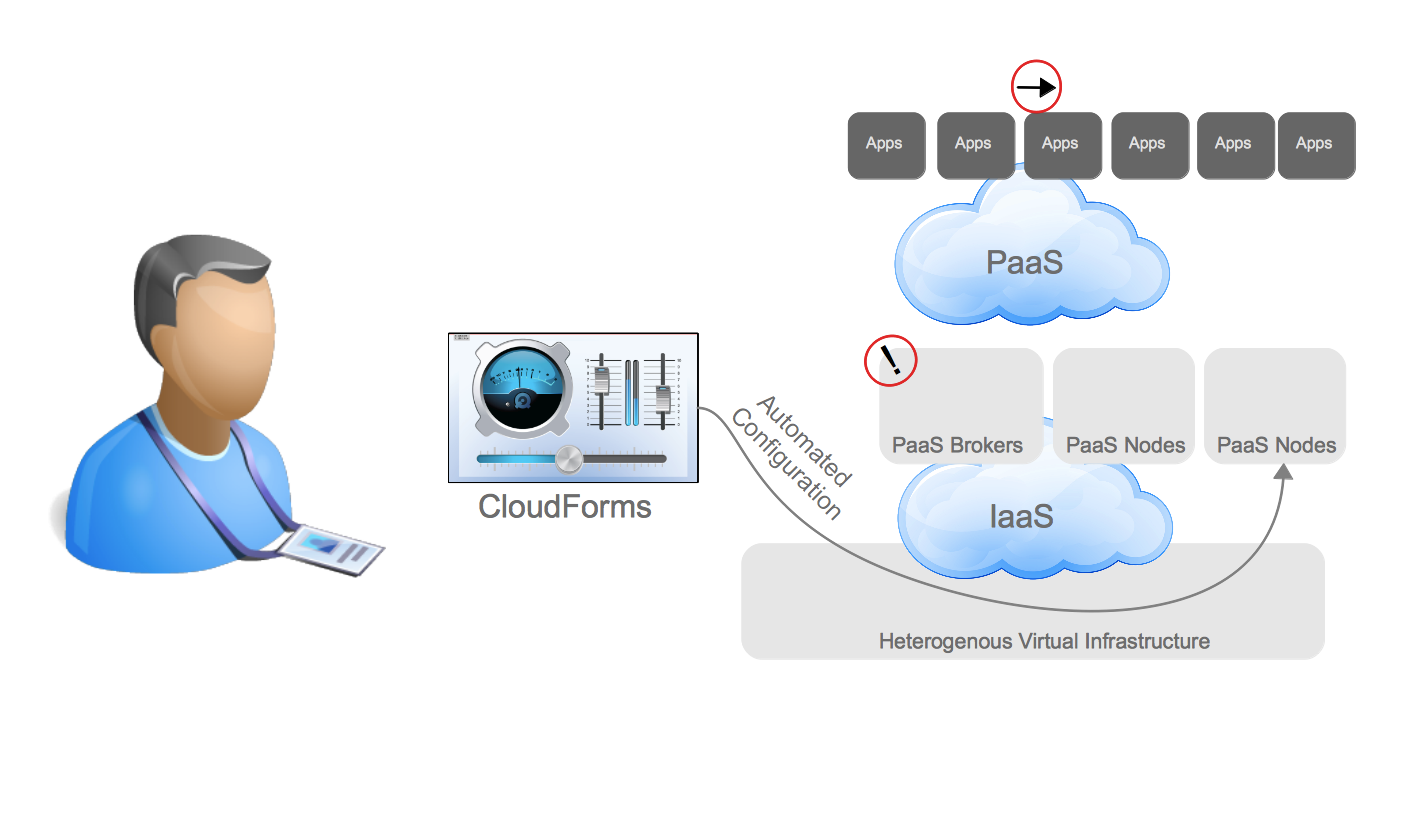
Finally, there is what I call the “Prescriptive Repeatable Build”. Similar to the other patterns the infrastructure including storage, network, and compute as a virtual machine or container are provisioned and configured by the system administration teams. Once this is complete a PaaS team provisions the PaaS using the infrastructure resources.
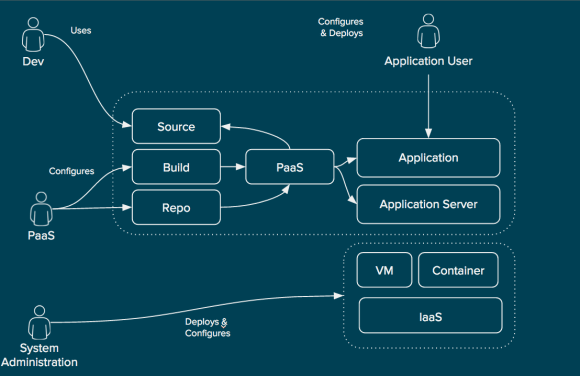
Prescriptive Repeatable Build (High Level)
The PaaS exposes a self-service user interface for developers to obtain a new environment. Along with an endpoint for the instantiated service the developer is provided with an endpoint for manipulating the configuration of the service (usually the application code itself, but sometimes other aspects as well).
General Trends
Most organizations have multiple service design and delivery patterns happening at the same time. Most also want to move from repeatable deployment to prescriptive repeatable build wherever possible. This is because high automation can generally be equated with delivery of more applications in a shorter period of time. It also provides a greater degree of standardization thus reducing complexity.
Pains, Challenges, and Limitations
There are several pains, challenges, and limitations within each pattern.
The Repeatable Deployment pattern is generally the easiest to implement of the three. It generally includes automating infrastructure deployments and sometimes even automates the configuration of the application servers. Still, the disconnected nature of development from the deployment, configuration, and operation of the application itself means the repeatable deployment does not provide as much value when it comes to delivering applications faster. It also tends to lead to greater amounts of human error when deploying applications since it often relies on tribal knowledge or manual tasks between development and operations to run an application.
The Custom Repeatable Builds provide end users with a means of updating their applications automatically. This pattern also accommodates the existing source to image process, developer experience, and business requirements without requiring large amounts of change. This flexibility does come with a downside in that it takes a long time to onboard tenants. As mentioned earlier, we found that it can take months to onboard a simple application. Since large organizations typically have thousands of applications and potentially hundreds of development teams this pattern also leads to an explosion of complexity.
The Prescriptive Repeatable Builds provide the most standardization and allows developers to take source to a running application quickly. However, it often requires a significant effort to change the build process to fit into it’s opinionated deployment style. This leads to a larger risk to user acceptance depending on how application development teams behave in an organization. In using an opinionated method, however, the complexity of the end state can be reduced.
Finally, moving between each of these patterns is painful for organizations. In most cases, it is impossible to leverage existing investments from one pattern in another. This means redesigning and reimplementing service design each time.
How do Organizations Decide which Approach is Best?
Deciding which pattern is best is dependent on many factors including (but not limited to):
- In-house skills
- Homogeneity of application development processes
- Business requirements driving application cycle time
- Application architecture
- Rigidity or flexibility of IT governance processes
The difference in pattern used on a per application basis is often the reason multiple patterns exist inside large organizations. For example, in a large organization that has grown through merger and acquisition there may be some application delivery teams that are building a Platform as a Service (PaaS) to enable prescriptive repeatable builds while others are using repeatable deployments and still others have hand crafted customized repeatable builds.
Principles for a Successful Service Design Solution
We have identified several principles that we believe a good service design solution should adhere to. This is not an exhaustive list. In no priority order they are:
- Create Separation of Service Design and Element Authoring
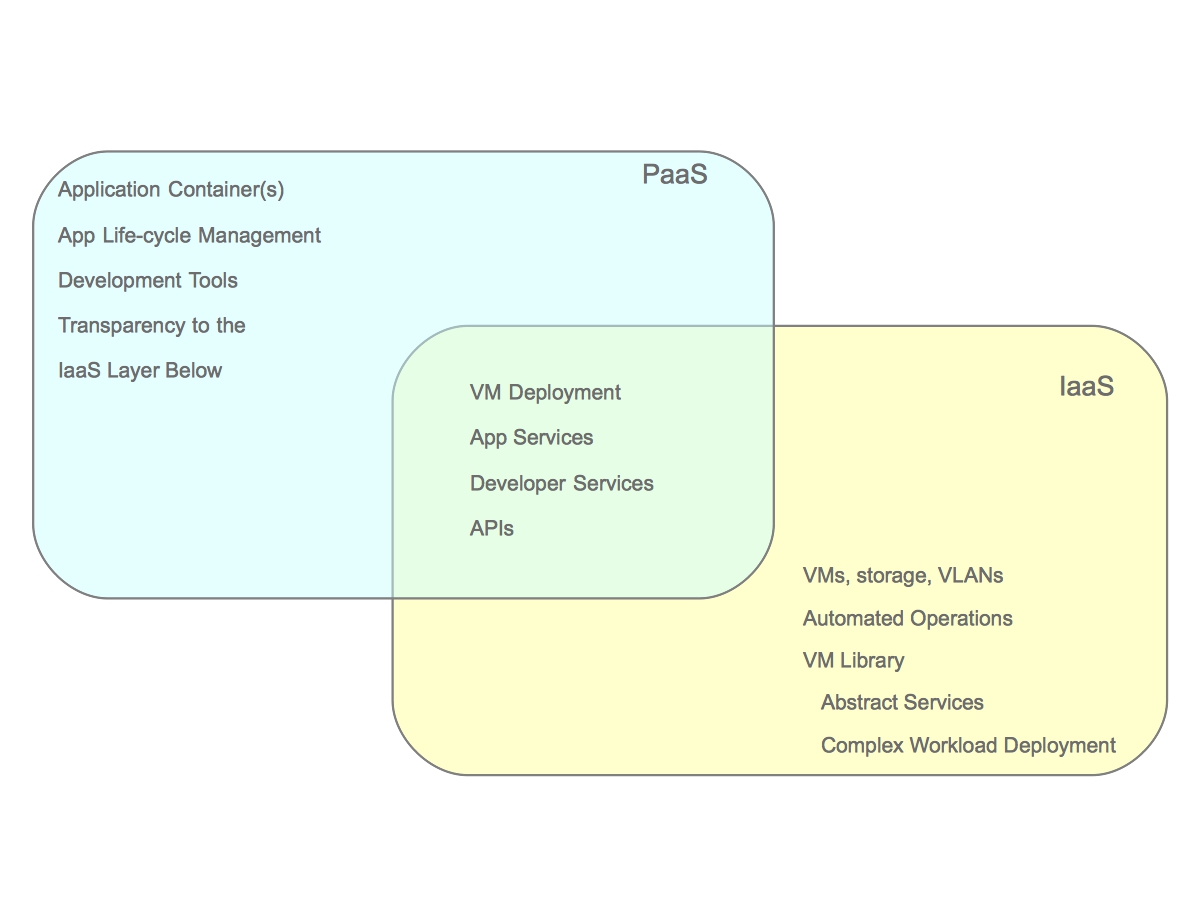
Each platform required to deliver either a repeatable deployment or repeatable build exposes its own set of elements. Infrastructure platforms might expose a Domain Specific Language (DSL) for describing compute, networking, and storage. Build systems may expose software projects and jobs. Automation and/or configuration management platforms may expose their own DSL. The list goes on. Each of the platforms has experts that author these. For example, an OpenShift PaaS platform expert will likely author a Kubernetes template. The service designer will not understand how to author this, but will need to discover the template and use it in the composition of a service. In other words: relate elements, don’t create elements.
- Provide Support for All Patterns
Not a single observed organization had one pattern. In fact, they all had multiple teams using multiple patterns. Solutions should take into account all the patterns observed or else they will fail to gain traction inside of organizations and provide efficiency.
- Allow for Evolution
Elements used in one pattern for service design should be able to be used in other service design patterns. For example, a virtual machine should be able to be a target for a repeatable deployment as well as a repeatable build. Failure to adhere to this will reduce the value of the solution as it will cause a high degree of duplication for end users.
- Provide Insight
We discovered that there were sections of automation in all the patterns that could be refactored into a declarative model (DSL) and away from an imperative model (workflow), but the designers of the service were either not aware of this or did not understand how to make the change. By providing insights to the service design about how to factor their service designs into the most declarative and portable model possible the solution could provide the most efficient and maintainable service design solution. Pattern recognition tools should be considered.
Improved Service Design Concept
An opportunity exists to greatly improve the service design experience. It can be possible to allow service designers to more easily design services using the widest range of items, accommodating the patterns required by the multiple teams inside most organization all while allowing the organization to evolve towards the prescriptive repeatable build pattern without losing their investments along the way. This concept allows for “services as code” and would provide a visual editor.
The concept begins with the discovery of existing elements within an organization’s platforms. For example, the discovery of a heat template from an OpenStack based IaaS platform or discovery of available repositories from a content system such as Nexus, Artifactory, or Red Hat Satellite. Discovery of these elements on a continual basis and ensuring they are placed into a source control system (or leveraging them from their existing source control systems).
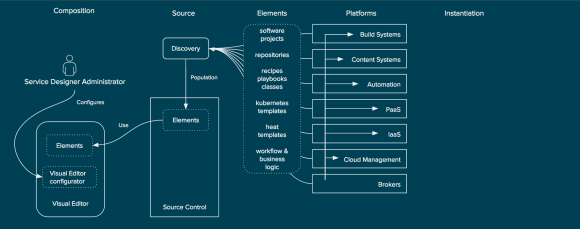
Discovery of Element for Service Composition
Once the elements are discovered and populated the visual editor can allow for the service designer to author a new service composition. This service composition would never create elements, but would describe how the elements are related.
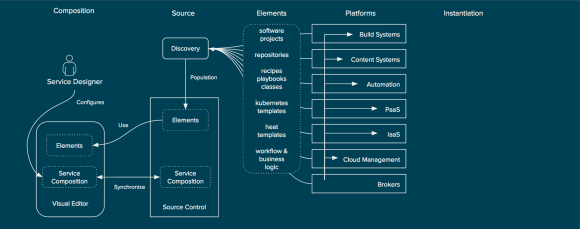
Composition of Elements
While out of scope for the concept of service design the service composition could be visualized to the service consumer within any number of service catalogs that can read the service composition. Also outside of the scope of service design (although also important), brokers can utilize the service composition to instantiate a running instance of the service across the platforms.
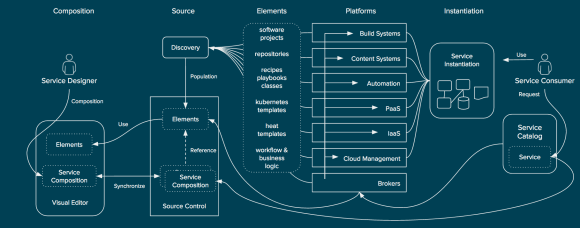
Publishing and Instantiation
Why does this matter to Red Hat?
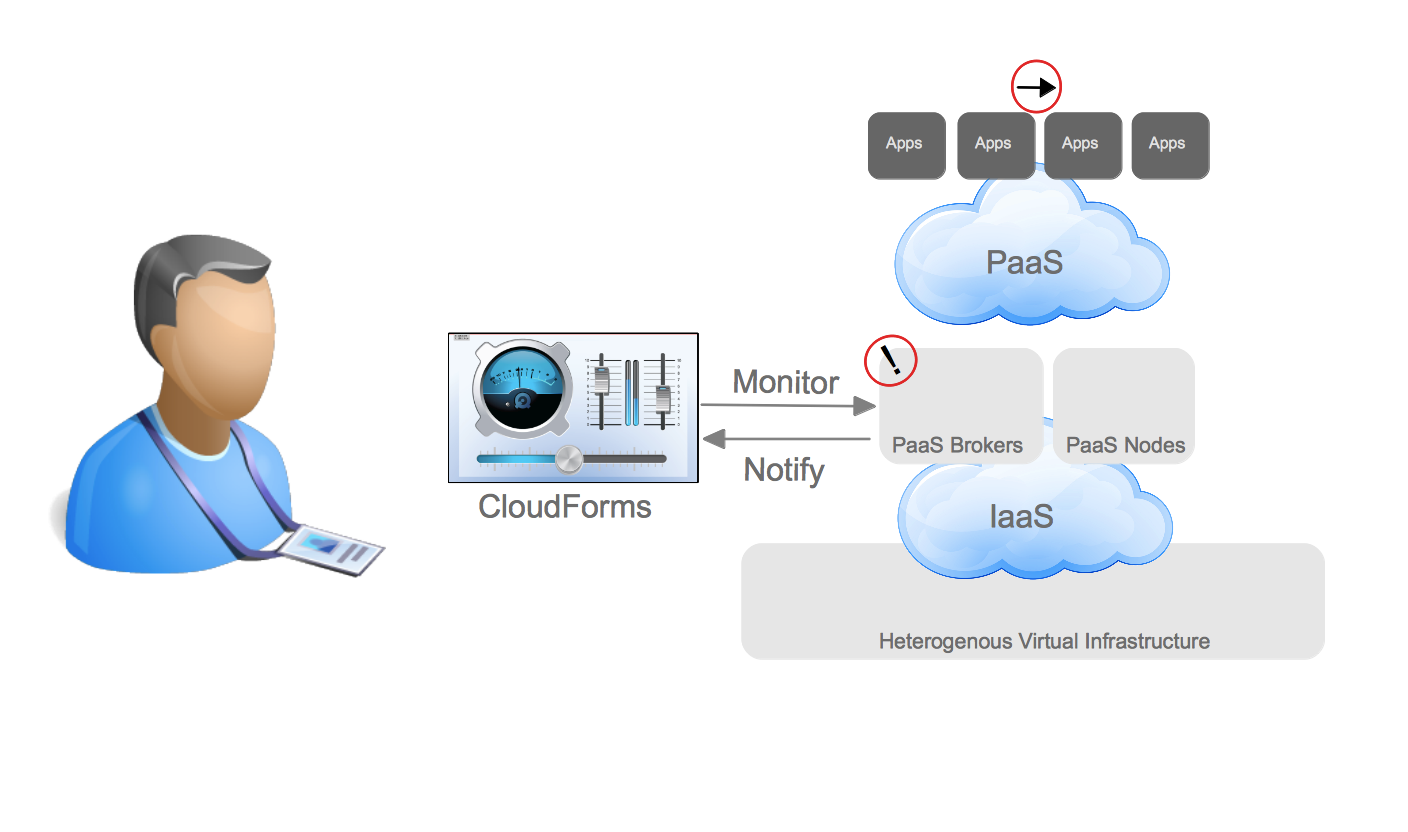
Red Hat has a unique opportunity to provide a uniform way of designing services across all three patterns using both their products as well as other leading solutions in the market. In providing a uniform way it would increase the usability and understanding between teams within our customers and allow for an easier transition between the patterns of repeatability while still allowing users to choose what pattern is right for them. This means a reduction in friction when introducing repeatable service delivery solutions. This would directly benefit products that provide repeatable deployments such as Ansible, Satellite, and CloudForms by improving the user experience. Then, as a customer matures, the concepts discussed here would provide them with an evolutionary path to repeatable builds that would not require reengineering a solution. This would greatly benefit products such as OpenStack and OpenShift.
What’s Next?
Currently, we are working through the user experience for designing a sample application within the concept in more detail. Once we complete this we hope to build a functional prototype of the concept and continue to improve the design to obtain market validation.
If you are a user that is interested in participating in our research or participating in co-creation please email me at jlabocki <at> redhat.com.