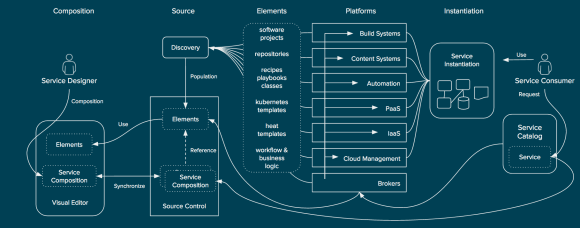
I’m often asked for a more in-depth overview of Red Hat Cloud Infrastructure (RHCI), Red Hat’s fully open source and integrated Infrastructure-as-a-Service offering. To that end I decided to write a brief technical introduction to RHCI to help those interested better understand what a typical deployment looks like, how the components interact, what Red Hat has been working on to integrate the offering, and some common use cases that RHCI solves. RHCI gives organizations access to infrastructure and management to fit their needs, whether it’s managed datacenter virtualization, a scale-up virtualization-based cloud, or a scale-out OpenStack-based cloud. Organizations can choose what they need to run and re-allocate their resources accordingly.

RHCI users can choose to deploy either Red Hat Enterprise Virtualization (RHEV) or Red Hat Enterprise Linux OpenStack Platform (RHEL-OSP) on physical systems to create a datacenter virtualization-based private cloud using RHEV or a private Infrastructure-as-a-Service cloud with RHELOSP.
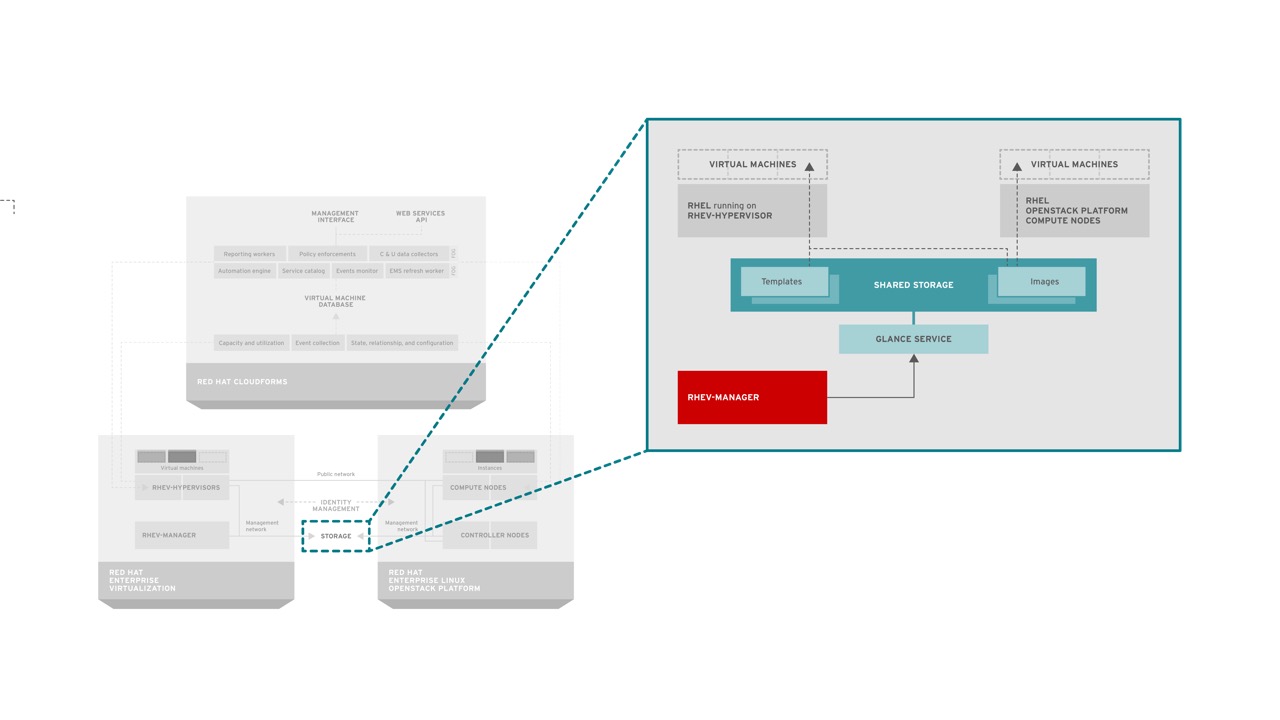
RHEV comprises a hypervisor component, referred to as RHEV-H, and a manager, referred to as RHEV-M. Hypervisors leverage shared storage and common networks to provide common enterprise virtualization features such as high availability, live migration, etc.
RHEL-OSP is Red Hat’s OpenStack distribution that provides massively scalable infrastructure by providing the following projects (descriptions taken directly from the projects themselves) for use on one of the largest ecosystems of certified hardware and software vendors for OpenStack:
Nova: Implements services and associated libraries to provide massively scalable, on demand, self service access to compute resources, including bare metal, virtual machines, and containers.
Swift: Provides Object Storage.
Glance: Provides a service where users can upload and discover data assets that are meant to be used with other services, like images for Nova and templates for Heat.
Keystone: Facilitate API client authentication, service discovery, distributed multi-tenant authorization, and auditing.
Horizon: Provide an extensible unified web- based user interface for all integrated OpenStack services.
Neutron: Implements services and associated libraries to provide on-demand, scalable, and technology-agnostic network abstraction.
Cinder: Implements services and libraries to provide on-demand, self-service access to Block Storage resources via abstraction and automation on top of other block storage devices.
Ceilometer: Reliably collects measurements of the utilization of the physical and virtual resources comprising deployed clouds, persist these data for subsequent retrieval and analysis, and trigger actions when defined criteria are met.
Heat: Orchestrates composite cloud applications using a declarative template format through an OpenStack-native ReST API.
Trove: Provides scalable and reliable Cloud Database as a Service functionality for both relational and non-relational database engines, and to continue to improve its fully-featured and extensible open source framework.
Ironic: Produces an OpenStack service and associated python libraries capable of managing and provisioning physical machines, and to do this in a security-aware and fault-tolerant manner.
Sahara: Provides a scalable data processing stack and associated management interfaces.
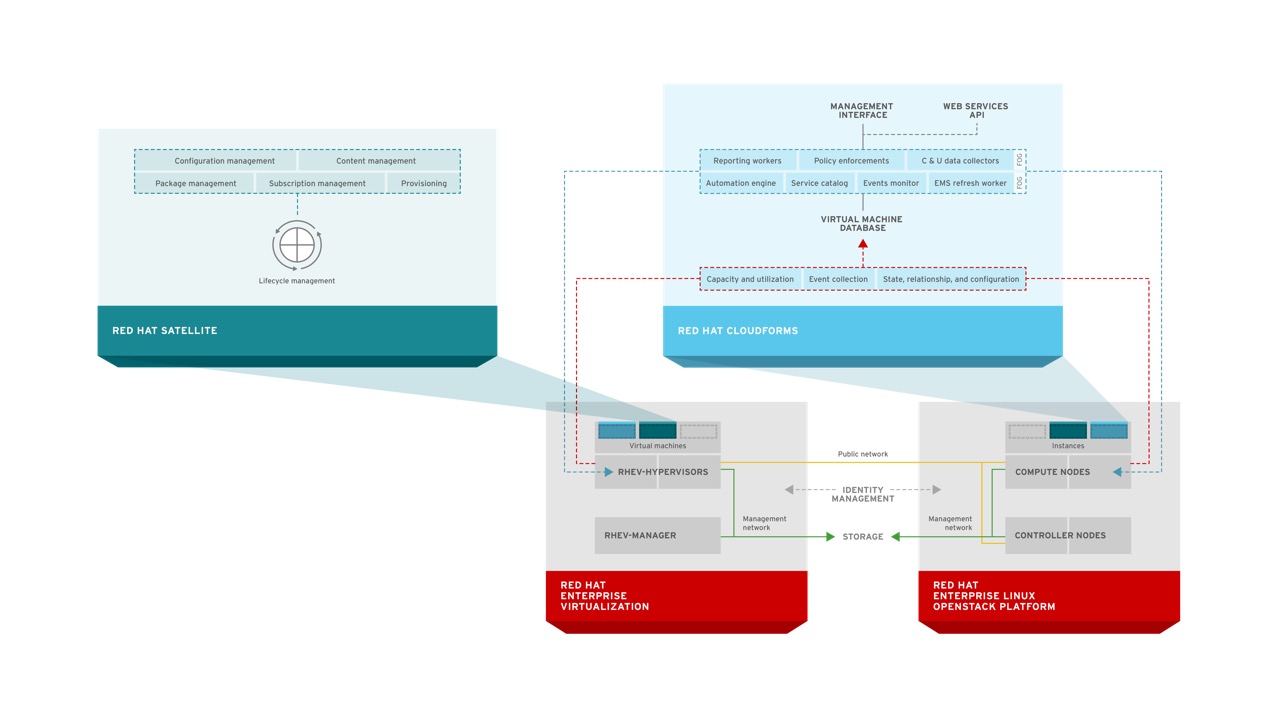
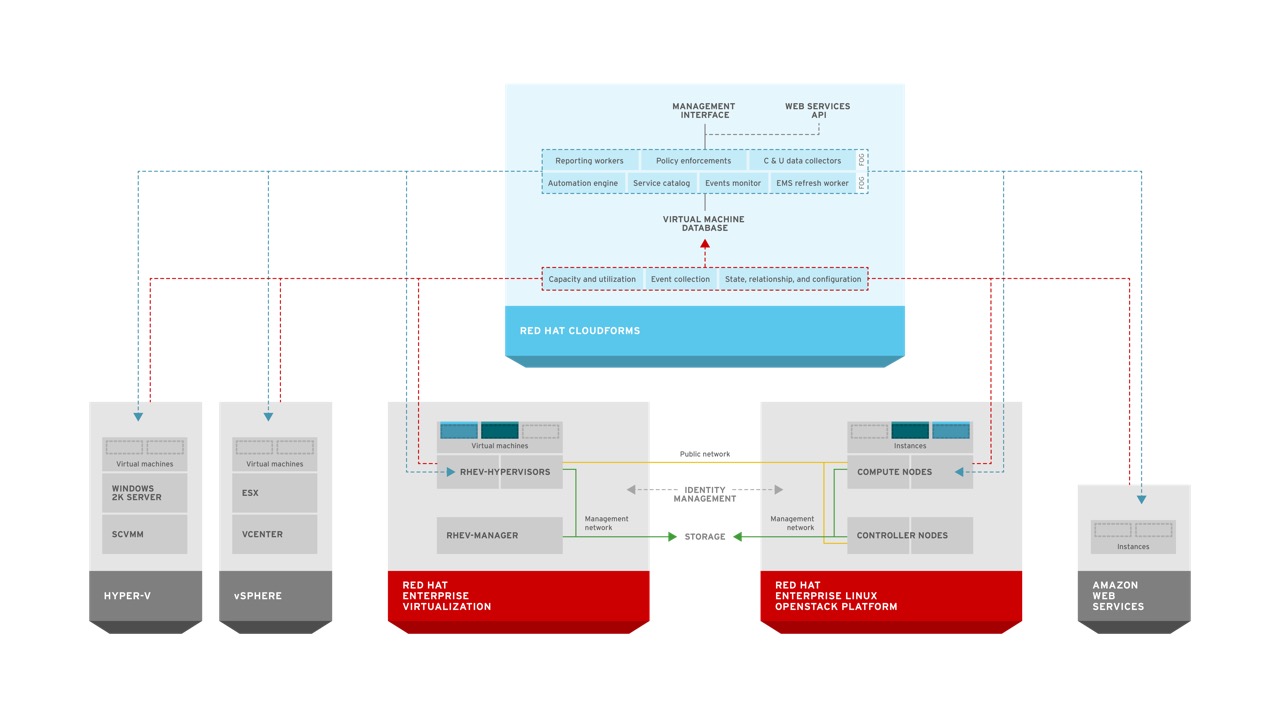
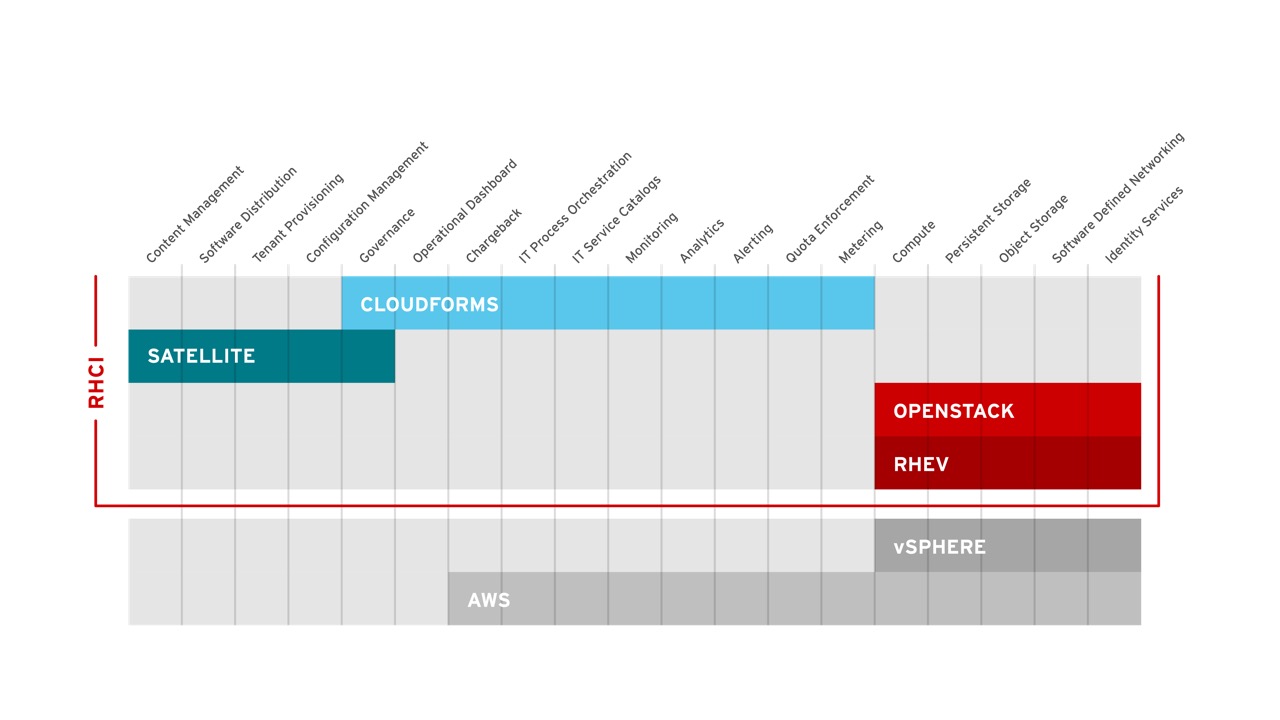
Red Hat CloudForms, a Cloud Management Platform based on the upstream ManageIQ project, provides hybrid cloud management of OpenStack, RHEV, Microsoft Hyper-V, VMware vSphere, and Amazon Web Services. This includes the ability to provide rich self-service with workflow and approval, discovery of systems, policy definition, capacity and utilization forecasting, and chargeback among others capabilities. CloudForms is deployed as a virtual appliance and requires no agents on the systems it manages. CloudForms has a region and zone concept that allows for complex and federated deployments across large environments and geographies.
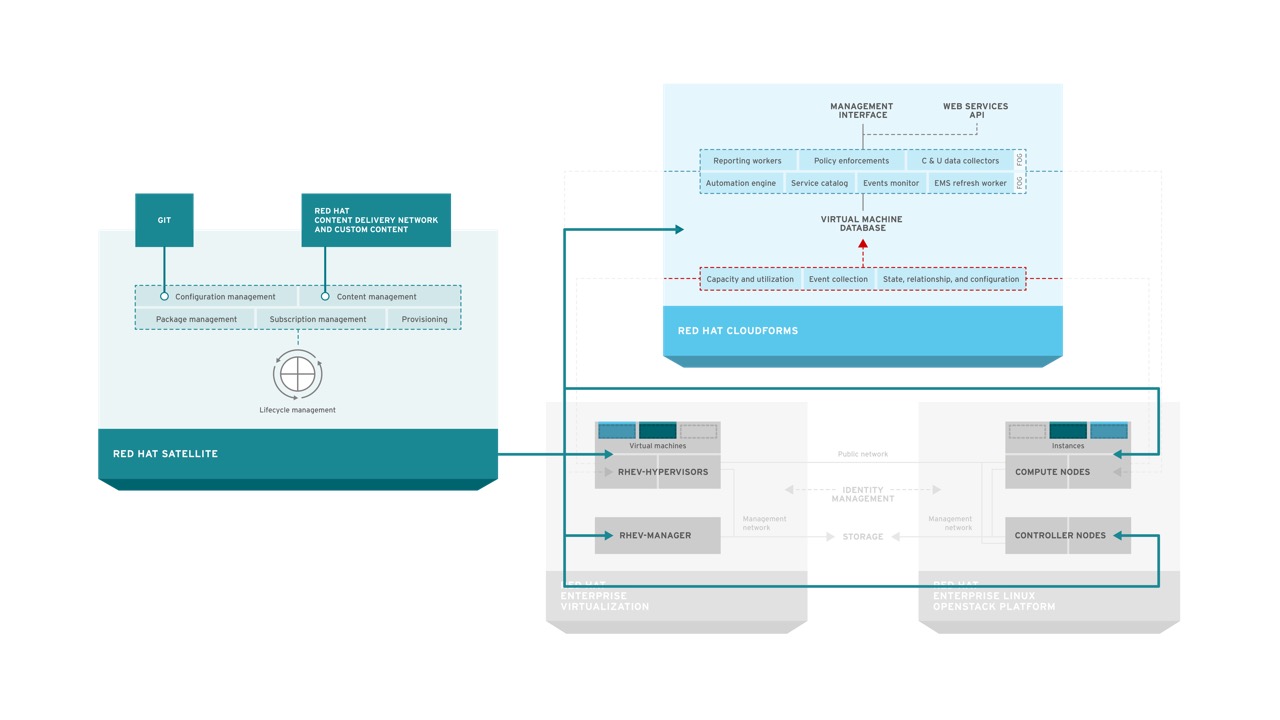
Red Hat Satellite is a systems management solution for managing the lifecycle of RHEV, RHEL-OSP, and CloudForms as well as any tenant workloads that are running on RHEV or RHEL-OSP. It can be deployed on bare metal or, as pictured in this diagram, as a virtual machine running on either RHEV or RHEL-OSP. Satellite supports a federated model through a concept called capsules.

CloudForms is a Cloud Management Platform that is deployed as a virtual appliance and supports a federated deployment. It is fully open source just as every component in RHCI is and is based on the ManageIQ project.
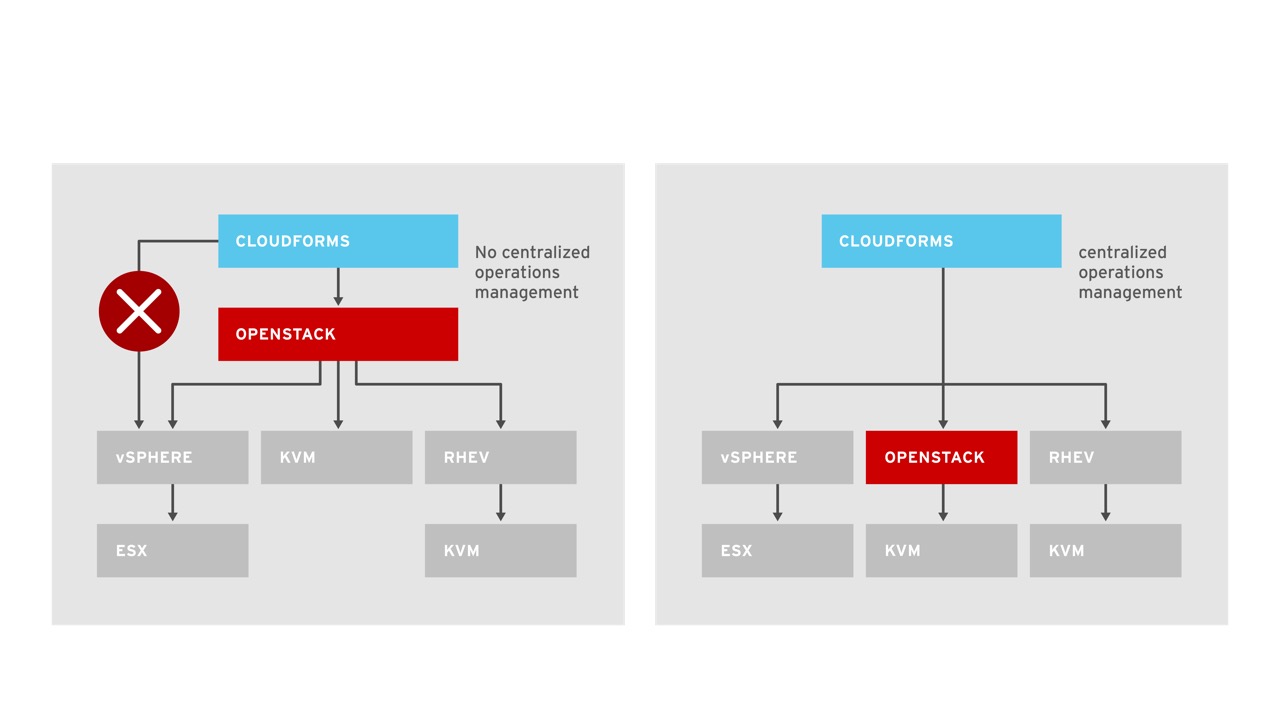
One of the key technical benefits CloudForms provides is unified management of multiple providers. CloudForms splits providers into two types. First, there are infrastructure providers such as RHEV, vSphere, and Microsoft Hyper-V. CloudForms discovers and provides uniform information about these systems hosts, clusters, virtual machines, and virtual machine contents in a single interface. Second, there are cloud providers such as RHEL-OSP and Amazon Web Services. CloudForms provides discovery and uniform information for these providers about virtual machines, images, flavors similar to the infrastructure providers. All this is done by leveraging standard APIs provided from RHEV-M, SCVMM, vCenter, AWS, and OpenStack.

Red Hat Satellite provides common systems management among all aspects of RHCI.
Red Hat Satellite provides content management, allowing users to synchronize content such as RPM packages for RHEV, RHEL-OSP, and CloudForms from Red Hat’s Content Delivery Network, to an on-premises Satellite reducing bandwidth consumption and providing an on-premises control point for content management through complex environments. Satellite also allows for configuration management via Puppet to ensure compliance and enforcement of proper configuration. Finally, Red Hat Satellite allows users to account for usage of assets through entitlement reporting and controls. Satellite provides these capabilities to RHEV, RHEL-OSP, and CloudForms, allowing administrators of RHCI to maintain their environment more effectively and efficiently. Equally as important is that Satellite also extends to the tenants of RHEV and RHEL-OSP to allow for systems management of Red Hat Enterprise Linux (RHEL) based tenants. Satellite is based on the upstream projects of Foreman, Katello, Pulp, and Candlepin.

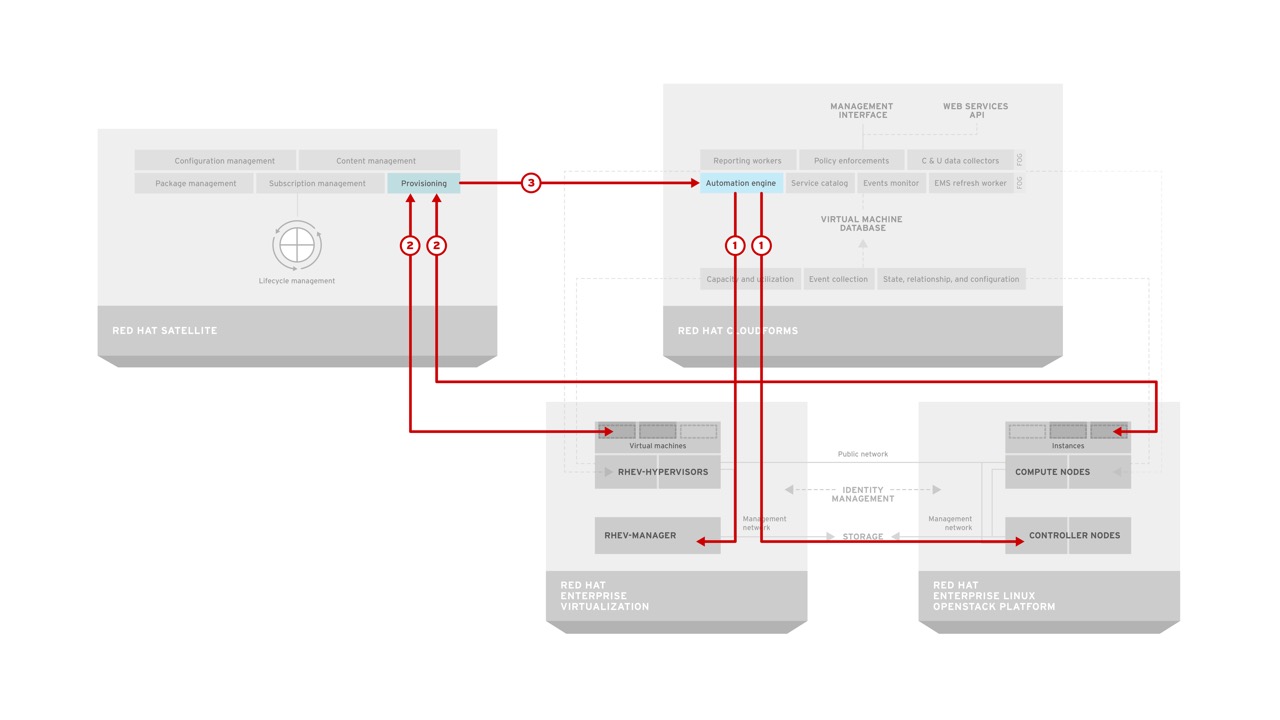
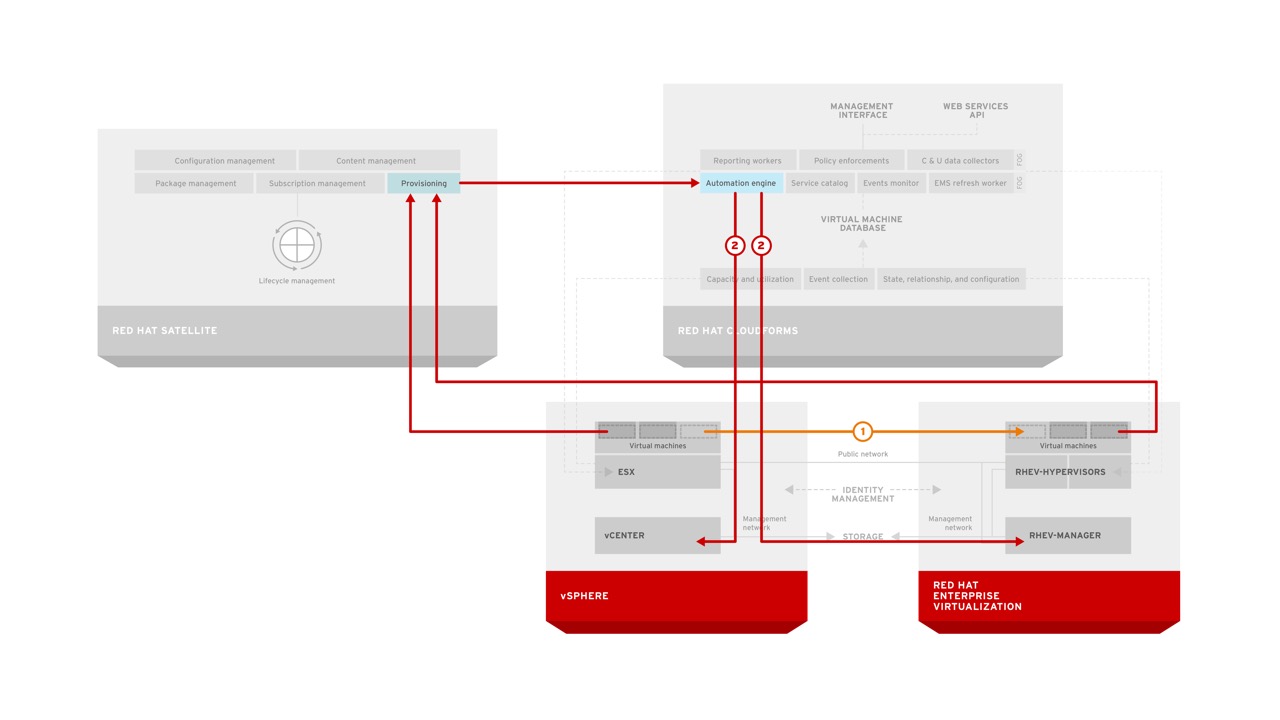
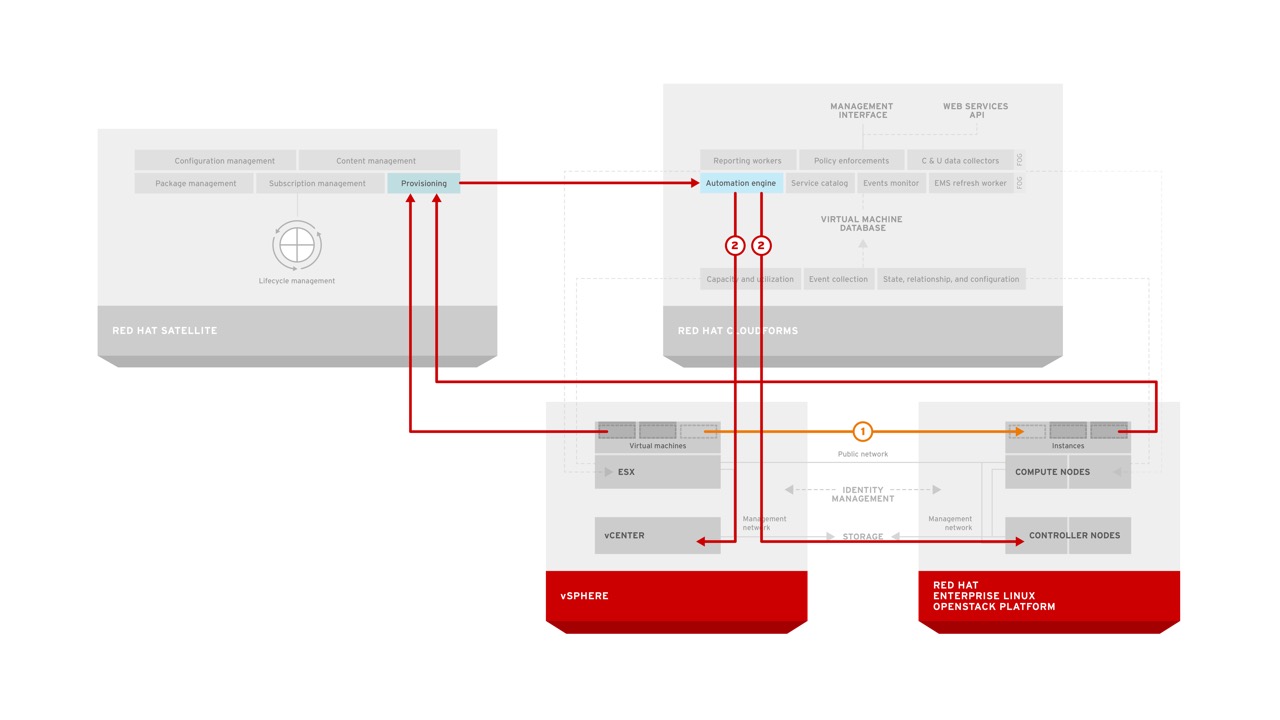
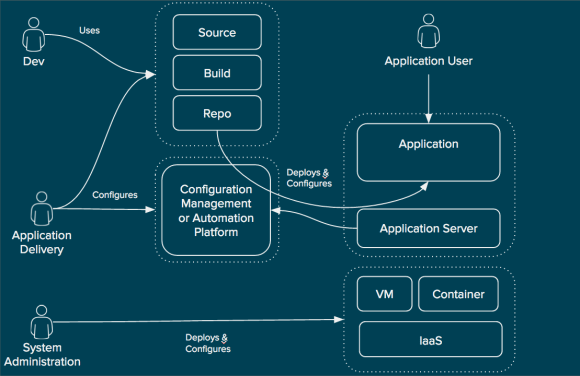
The combination of CloudForms and Satellite is very powerful for automating not only the infrastructure, but within the operating system as well. Let’s look at an example of how CloudForms can be utilized with Satellite to provide automation of deployment and lifecycle management for tenants.
The automation engine in CloudForms is invoked when a user orders a catalog item from the CloudForms self-service catalog. CloudForms communicates with the appropriate infrastructure provider (in this case RHEV or RHEL-OSP pictured) to ensure that the infrastructure resources are created. At the same time it also ensures the appropriate records are created in Satellite so that the proper content and configuration will be applied to the system. Once the infrastructure resources are created (such as a virtual machine), they are connected to Satellite where they receive the appropriate content and configuration. Once this is completed, the service in CloudForms is updated with the appropriate information to reflect the state of the users request allowing them access to a fully compliant system with no manual interaction during configuration. Ongoing updates of the virtual machine resources can be performed by the end user or the administrator of the Satellite dependent on the customer needs.

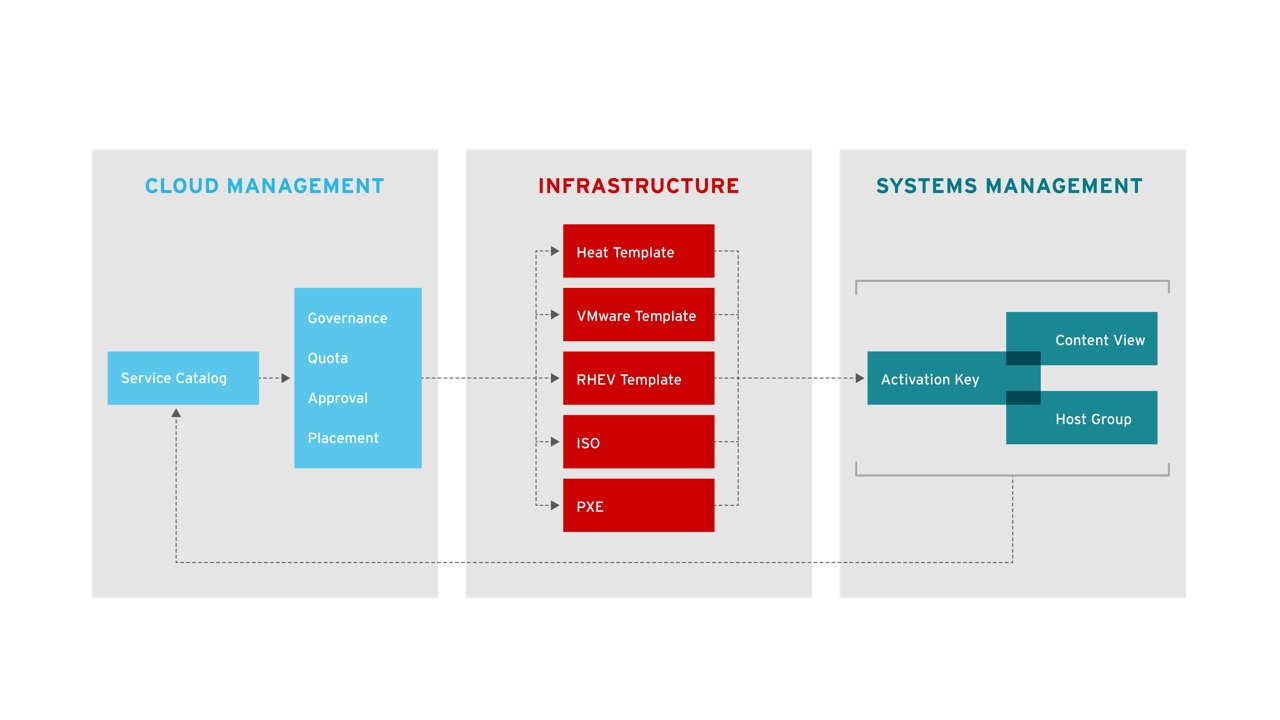
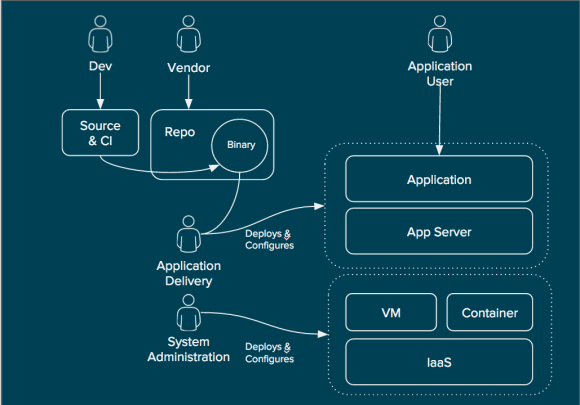
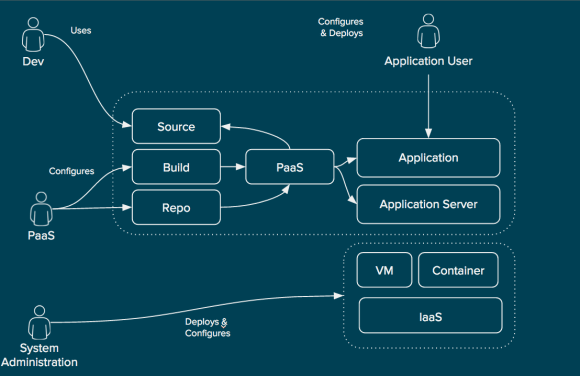
This is another way of looking at how the functional areas of the workflow are divided in RHCI. Items such as the service catalog, quota enforcement, approvals, and workflow are handled in CloudForms, the cloud management platform. Even still, infrastructure-specific mechanisms such as heat templates, virtual machine templates, PXE, or even ISO-based deployment are utilized by the cloud management platform whenever possible. Finally, systems management is used to provide further customization within the operating system itself that is not covered by infrastructure specific provisioning systems. With this approach, users can separate operating system configuration from the infrastructure platform thus increasing portability. Likewise, operational decisions are decoupled from the infrastructure platform and placed in the cloud management platform allowing for greater flexibility and increased modularity.

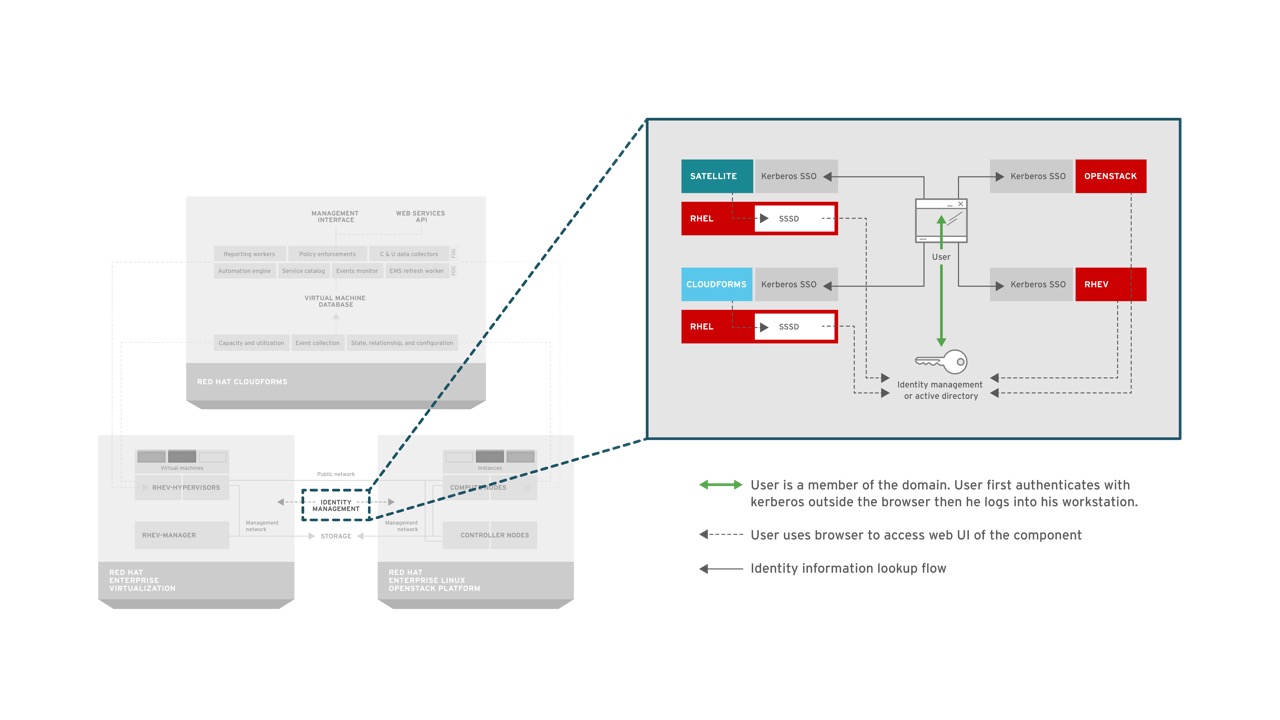
Common management is a big benefit that RHCI brings to organizations, but it doesn’t stop there. RHCI is bringing together the benefits of shared services to reduce the complexity for organizations. Identity is one of the services that can be made common across RHCI through the use of Identity Management (IDM) that is included in RHEL. All components of RHCI can be configured to talk to IDM which in turn can be used to authenticate and authorize users. Alternatively, and perhaps more frequently, a trust is established between IDM and Active Directory to allow for authentication via Active Directory. By providing a common identity store between the components of RHCI, administrators can ensure compliance through the use of access controls and audit.

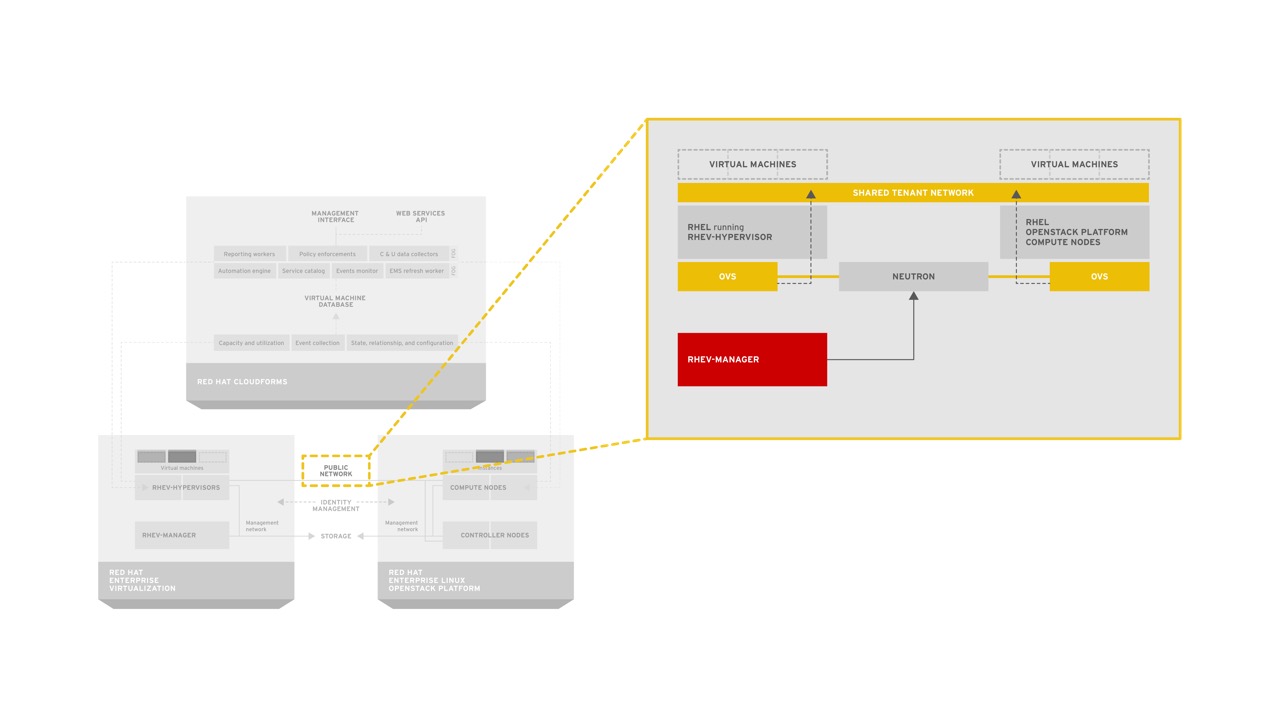
Similar to the benefits of shared identity, RHCI is bringing together a common network fabric for both traditional datacenter virtualization and infrastructure-as-a-service (IaaS) models. As part of the latest release of RHEV, users can now discover neutron networks and begin exposing them to guest virtual machines (in tech preview mode). By building a common network fabric organizations can simplify their architecture. No longer do they need to learn two different methods for creating and maintaining virtual networks.

Finally, Image storage can now be shared between RHEV and RHEL-OSP. This means that templates and images stored in Glance can be used by RHEV. This reduces the amount of storage required to maintain the images and allows administrators to update images in one store instead of two, increasing operational efficiency.

One often misunderstood area is around what capabilities are provided by which components of RHCI. RHEV and OpenStack provide similar capabilities with different paradigms. These focus around compute, network, and storage virtualization. Many of the capabilities often associated with a private cloud include features found in the combination of Satellite and CloudForms. These include capabilities provided by CloudForms such as discovery, chargeback, monitoring, analytics, quota Enforcement, capacity planning, and governance. They also include capabilities that revolve around managing inside the guest operating system in areas such as content management, software distribution, configuration management, and governance.

Often organizations are not certain about the best way to view OpenStack in relation to their datacenter virtualization solution. There are two common approaches that are considered. Within one approach, datacenter virtualization is placed underneath OpenStack. This approach has several negative aspects. First, it places OpenStack, which is intended for scale out, over an architecture that is designed for scale up in RHEV, vSphere, Hyper-V, etc. This gives organizations limited scalability and, in general, an expensive infrastructure for running a scale out IaaS private cloud. Second, layering OpenStack, a Cloud Infrastructure Platform, on top of yet another infrastructure management solution makes hybrid cloud management very difficult because Cloud Management Platforms, such as CloudForms, are not designed to relate OpenStack to a virtualization manager and then to underlying hypervisors. Conversely, by using a Cloud Management Platform as the aggregator between infrastructure platforms of OpenStack, RHEV, vSphere, and others, it is possible to achieve a working approach to hybrid cloud management and use OpenStack in the massively scalable way it is designed to be used.

RHCI is meant to complement existing investments in datacenter virtualization. For example, users often utilize CloudForms and Satellite to gain efficiencies within their vSphere environment while simultaneously increasing the cloud-like capabilities of their virtualization footprints through self-service and automation. Once users are comfortable with the self-service aspects of CloudForms, it is simple to supplement vSphere with lower cost or specialized virtualization providers like RHEV or Hyper-V.
This can be done by leveraging the virt-v2v tools (shown as option 1 in the diagram above) that perform binary conversion of images in an automated fashion from vSphere to other platforms. Another approach is to standardize environment builds within Satellite (shown as option 2 in the diagram above) to allow for portability during creation of a new workload. Both of these methods are supported based on an organization’s specific requirements.

For scale-out applications running on an existing datacenter virtualization solution such as VMware vSphere RHCI can provide organizations with the tools to identify (discover), and move (automated v2v conversion), workloads to Red Hat Enterprise Linux OpenStack Platform where they can take advantage of massive scalability and reduced infrastructure costs. This again can be done through binary conversion (option 1) using CloudForms or through standardization of environments (option 2) using Red Hat Satellite.

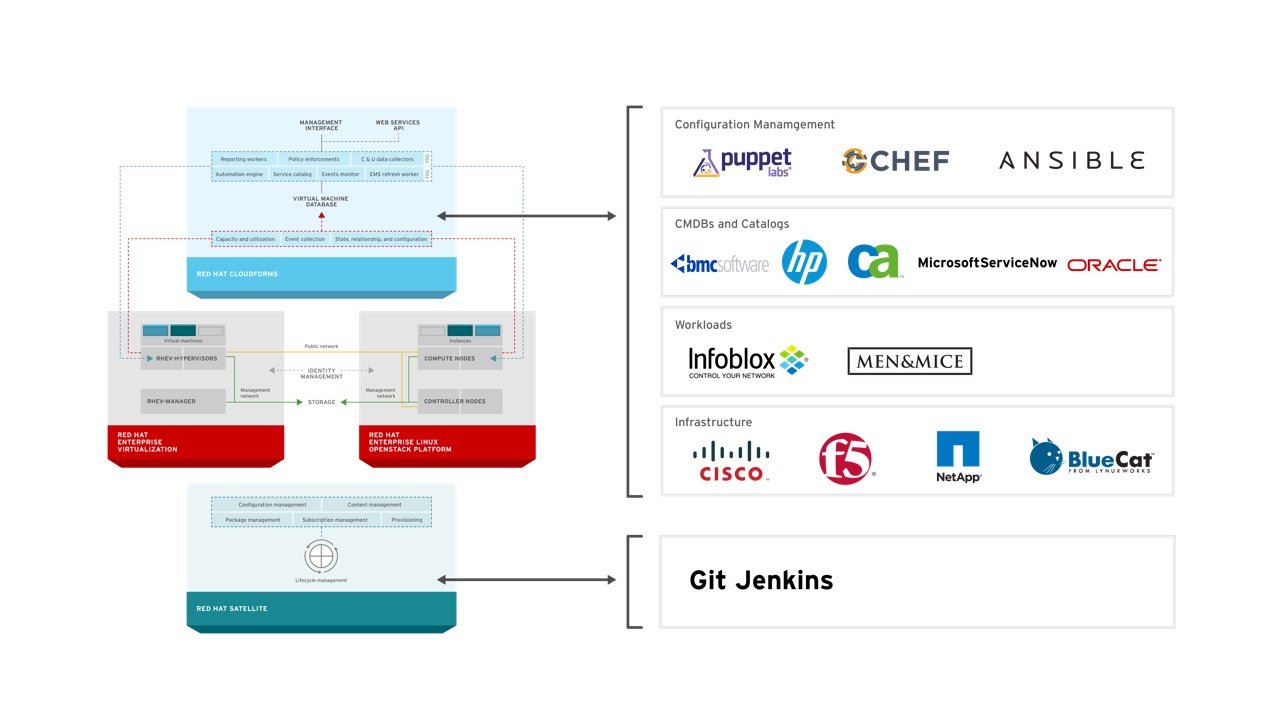
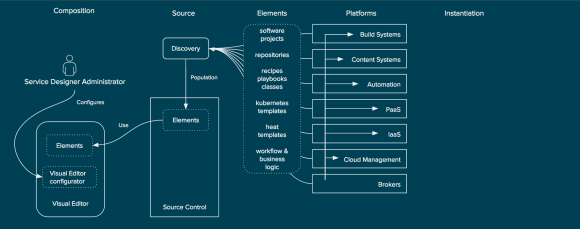
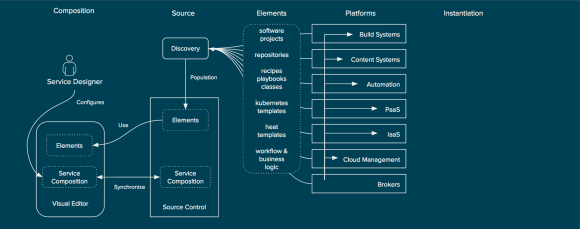
So far I have focused primarily on the integrations between the components of Red Hat Cloud Infrastructure to illustrate how Red Hat is bringing together a comprehensive Infrastructure-as-a-Service solution, but RHCI integrates with many existing technologies within the management domain. From integrations with configuration management solutions such as Puppet, Chef, and Ansible, and many popular Configuration Management Databases (CMDBs) as well networking providers and IPAM systems, CloudForms and Satellite are extremely extensible to ensure that they can fit into existing environments.

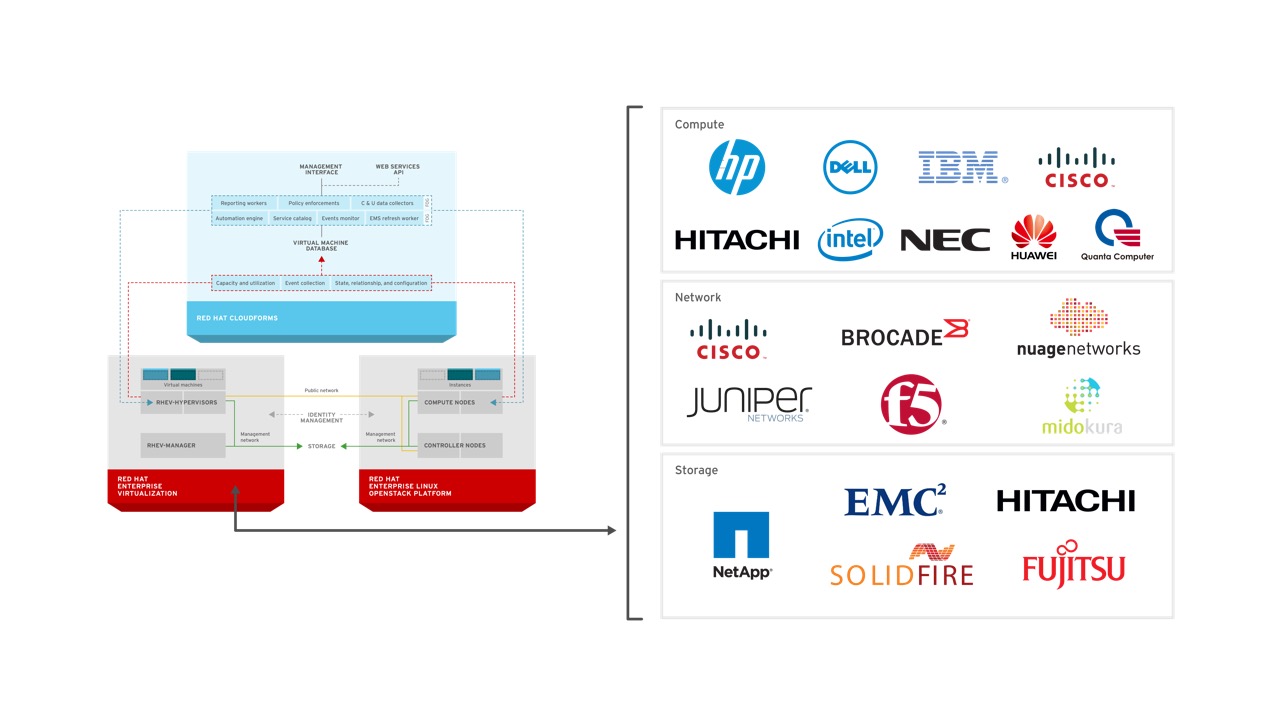
And of course, with Red Hat Enterprise Linux forming the basis of both Red Hat Enterprise Virtualization and Red Hat Enterprise Linux OpenStack Platform leading to one of the largest ecosystems of certified compute, network, and storage partners in the industry.
RHCI is a complete and fully open source infrastructure-as-a-service private cloud. It has industry leading integration between a datacenter virtualization and openstack based private cloud in the areas of networking, storage, and identity. A common management framework makes for efficient operations and unparallelled automation that can also span other providers. Finally, by leveraging RHEL and Systems Management and Cloud Management Platform based on upstream communities it has a large ecosystem of hardware and software partners for both infrastructure and management.
I hope this post helped you gain a better understanding of RHCI at a more technical level. Feel free to comment and be sure to follow me on twitter @jameslabocki
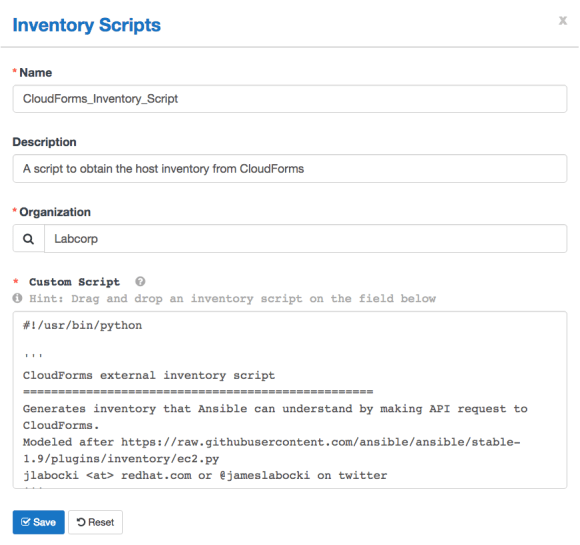
 From there select the icon to add a new inventory script. You can now add the inventory script and name it and associate it with your organization.
From there select the icon to add a new inventory script. You can now add the inventory script and name it and associate it with your organization.