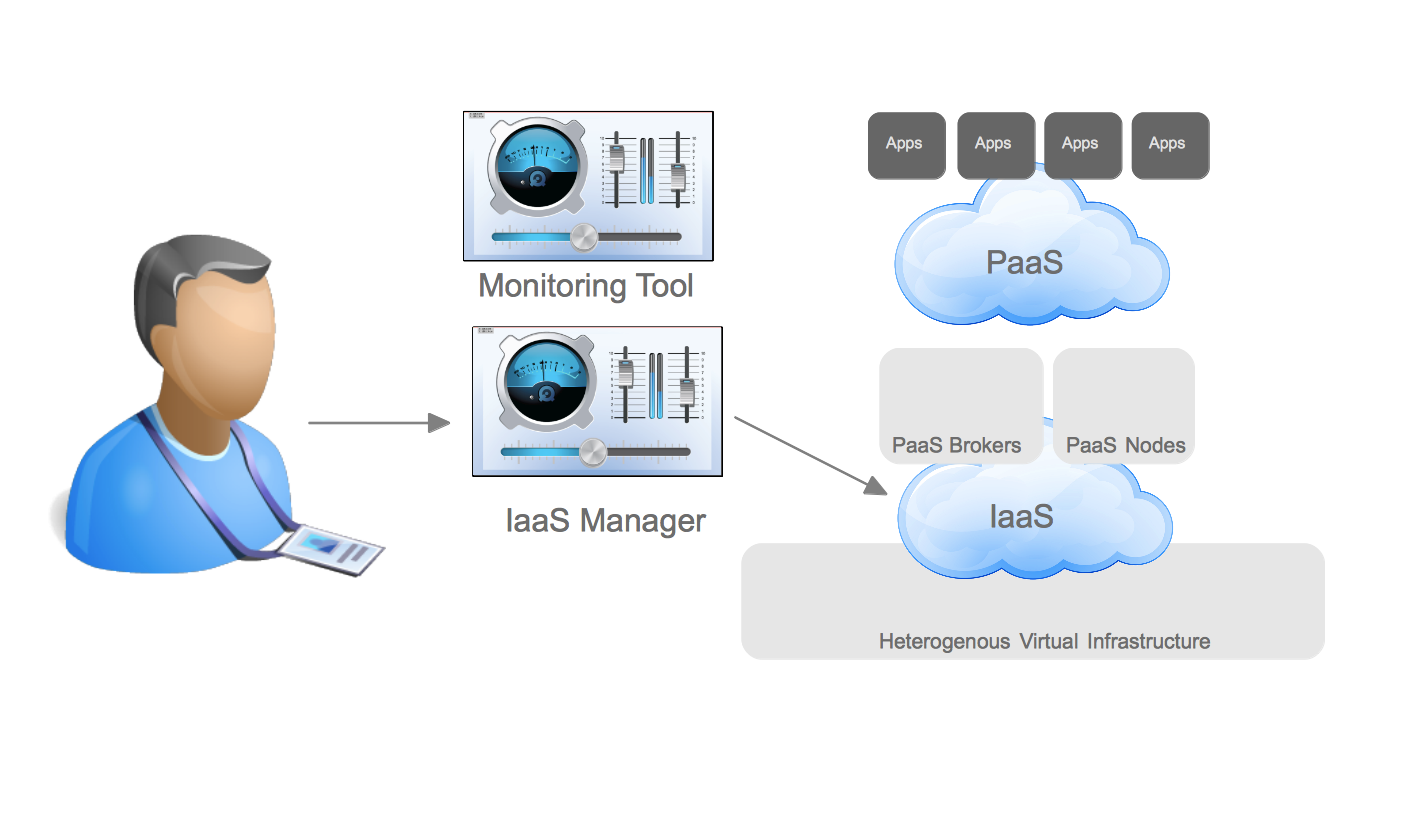
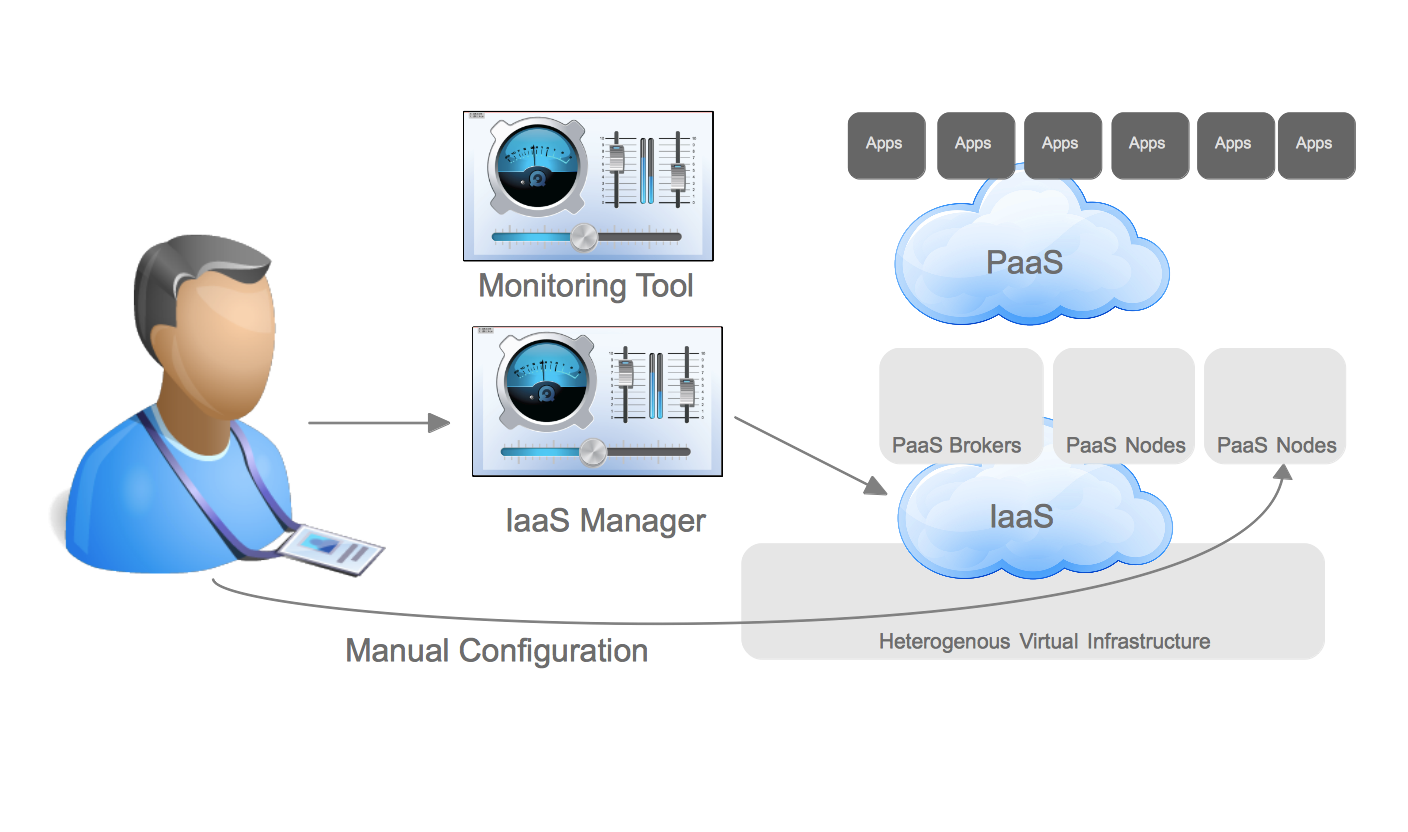
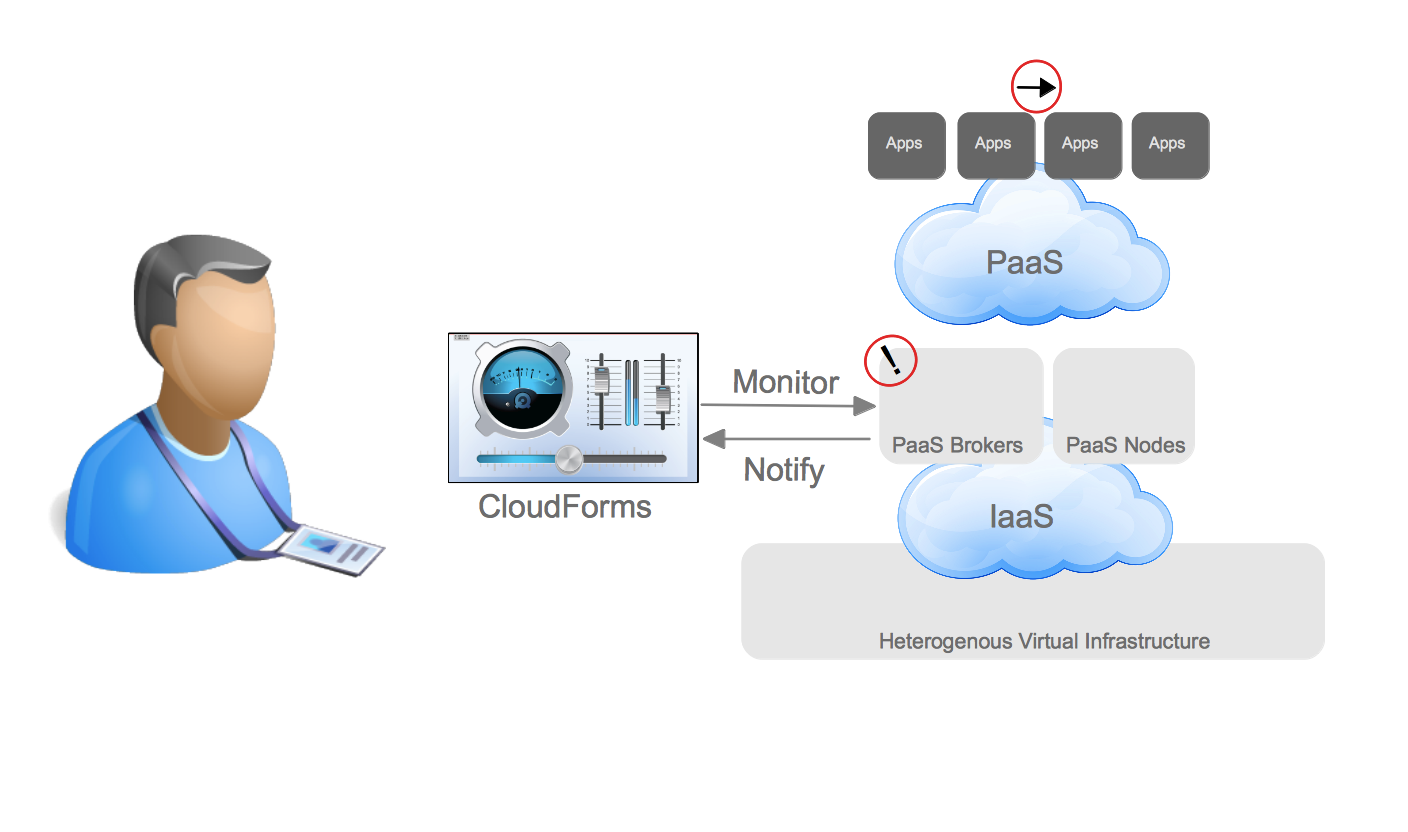
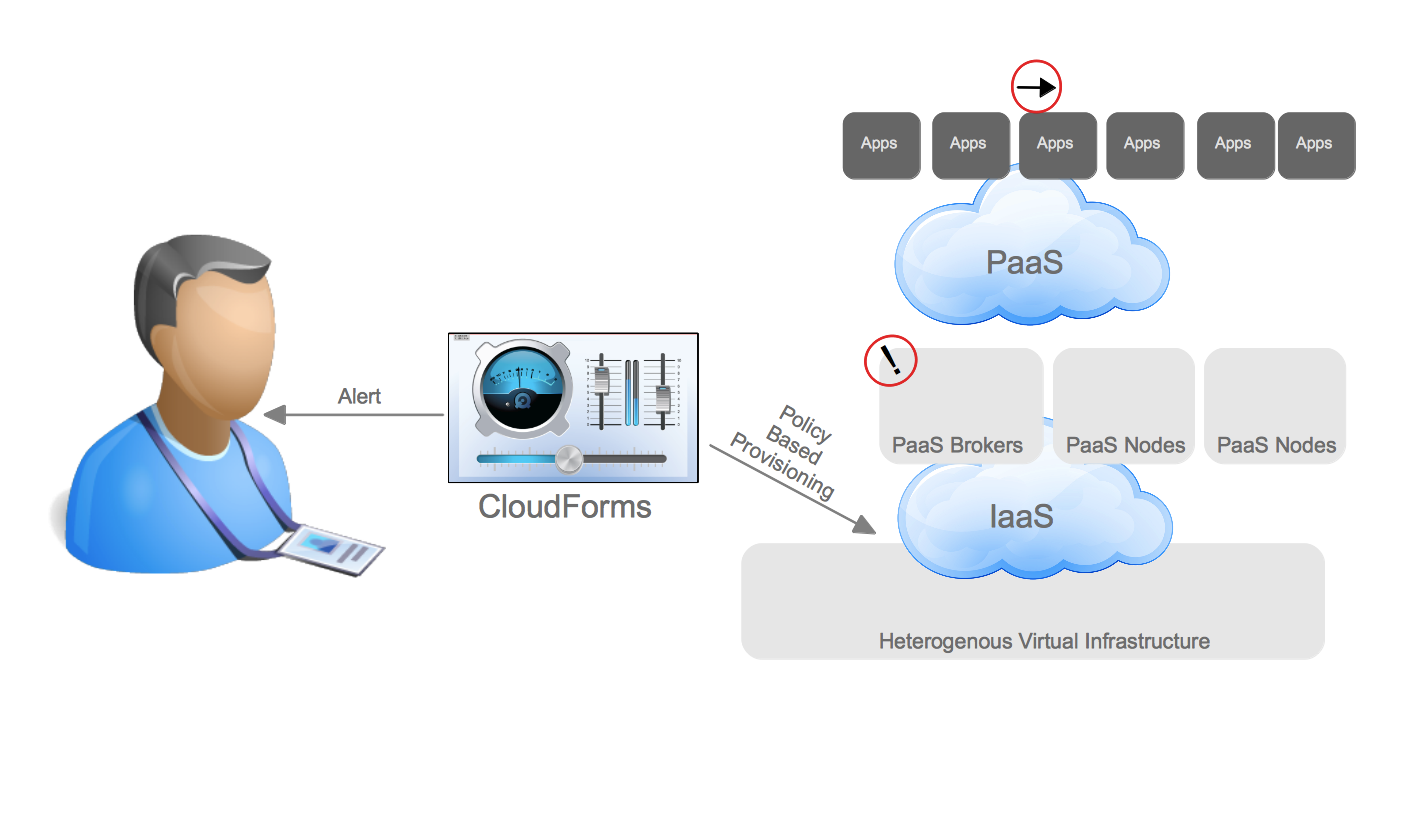
Packstack makes installing OpenStack REALLY easy. By using the –allinone option you could have a working self-contained RDO installation in minutes (and most of those minutes are spent waiting for packages to install). However, the –allinone option really should be renamed to the –onlywithinone today, because while it makes the installation very simple it doesn’t allow for instances spun up on the resulting OpenStack environment to be reachable from external systems. This can be a problem if you are trying to both bring up an OpenStack environment quickly and demonstrate integration with systems outside of OpenStack. With a lot of help and education from Perry Myers and Terry Wilson on Red Hat’s RDO team I was able to make a few modifications to the packstack installation to allow a user to use the packstack installation with –allinone and have external access to the instances launched on the host. While I’m not sure this is the best practice for setup here is how it works.
I started with a @base kickstart installation of Red Hat Enterprise Linux 6.4. First, I subscribed the system via subscription manager and subscribed to the rhel server repository. I also installed the latest RDO repository file for Grizzly and then updated the system and installed openvswitch. The update will install a new kernel.
# subscription-manager register ... # subscription-manager list --available |egrep -i 'pool|name' ... # subscription-manager attach --pool=YOURPOOLIDHERE ... # rpm -ivh http://rdo.fedorapeople.org/openstack/openstack-grizzly/rdo-release-grizzly.rpm ... # yum -y install openvswitch ... # yum -y update
Before I rebooted I setup a bridge named br-ex by placing the following in /etc/sysconfig/network-scripts/ifcfg-br-ex.
DEVICE=br-ex OVSBOOTPROTO=dhcp OVSDHCPINTERFACES=eth0 NM_CONTROLLED=no ONBOOT=yes TYPE=OVSBridge DEVICETYPE=ovs
I also changed the setup of the eth0 interface by placing the following in /etc/sysconfig/network-scripts/ifcfg-eth0. The configuration would make it belong to the bridge we previously setup.
DEVICE="eth0" HWADDR="..." TYPE=OVSPort DEVICETYPE=ovs OVS_BRIDGE=br-ex UUID="..." ONBOOT=yes NM_CONTROLLED=no
At this point I rebooted the system so the updated kernel could be used. When it comes back up you should have a bridged interface named br-ex which has the IP address that was associated with eth0. I had a static leased DHCP entry for eth0 prior to starting, so even though the interface was set to use DHCP as it’s bootproto it receives the same address consistently.
Now you need to install packstack.
# yum -y install openstack-packstack
Packstack’s installation accepts an argument named quantum-l3-ext-bridge.
–quantum-l3-ext-bridge=QUANTUM_L3_EXT_BRIDGE
The name of the bridge that the Quantum L3 agent will
use for external traffic, or ‘provider’ if using
provider networks
We will set this to eth0 so that the eth0 interface is used for external traffic. Remember, eth0 will be a port on br-ex in openvswitch, so it will be able to talk to the outside world through it.
Before we run the packstack installer though, we need to make another change. Packstack’s –allinone installation uses some puppet templates to provide answers to the installation options. It’s possible to override the options if there is a command line switch, but packstack doesn’t accept arguments for everything. For example, if you want to change the floating IP range to fall in line with the network range your eth0 interface supports then you’ll need to edit a puppet template by hand.
Edit /usr/lib/python2.6/site-packages/packstack/puppet/modules/openstack/manifests/provision.pp and change $floating_range to a range that is suitable for the network eth0 is on. The floating range variable appears to be used for assigning the floating IP address pool ranges by packstack when –allinone is used.
One last modification before we run packstack, and thanks to Terry Wilson for pointing this out, we need to remove a a firewall rule that is added during the packstack run that adds a NAT rule which will effectively block inbound traffic to a launched instance. You can edit /usr/lib/python2.6/site-packages/packstack/puppet/templates/provision.pp and comment out the following lines.
firewall { '000 nat':
chain => 'POSTROUTING',
jump => 'MASQUERADE',
source => $::openstack:rovision::floating_range,
outiface => $::gateway_device,
table => 'nat',
proto => 'all',
}
The ability to configure these via packstack arguments should eventually make it’s way into packstack. See this Bugzilla for more information.
That’s it, now you can fire up packstack by running the following command.
packstack --allinone —quantum-l3-ext-bridge=eth0
When it completes it will tell you that you need to reboot for the new kernel to take effect, but you don’t need to since we already updated after running yum update with the RDO repository in place.
Your openvswitch configuration should look roughly like this when packstack finishes running.
# ovs-vsctl show
08ad9137-5eae-4367-8c3e-52f8b87e5415
Bridge br-int
Port "tap46aaff1f-cd"
tag: 1
Interface "tap46aaff1f-cd"
type: internal
Port br-int
Interface br-int
type: internal
Port "qvod54d32dc-0b"
tag: 1
Interface "qvod54d32dc-0b"
Port "qr-0638766f-76"
tag: 1
Interface "qr-0638766f-76"
type: internal
Bridge br-ex
Port br-ex
Interface br-ex
type: internal
Port "qg-3f967843-48"
Interface "qg-3f967843-48"
type: internal
Port "eth0"
Interface "eth0"
ovs_version: "1.11.0"
Before we start provisioning instances in Horizon let’s take care of one last step and add two security group rules to allow ssh and icmp to our instances.
# . ~/keystonerc_demo # nova secgroup-add-rule default icmp -1 -1 0.0.0.0/0 # nova secgroup-add-rule default tcp 22 22 0.0.0.0/0
Now you can log into horizon with the demo user whose credentials are stored in /root/keystonerc_demo and provision an instance. Make sure you specify the private network for this instance. The private network is automatically created for the demo tenant by the packstack –allinone installation. You’ll also notice it uploaded an image named cirros into glance for you. Of course, this assumes you’ve already created a keypair.
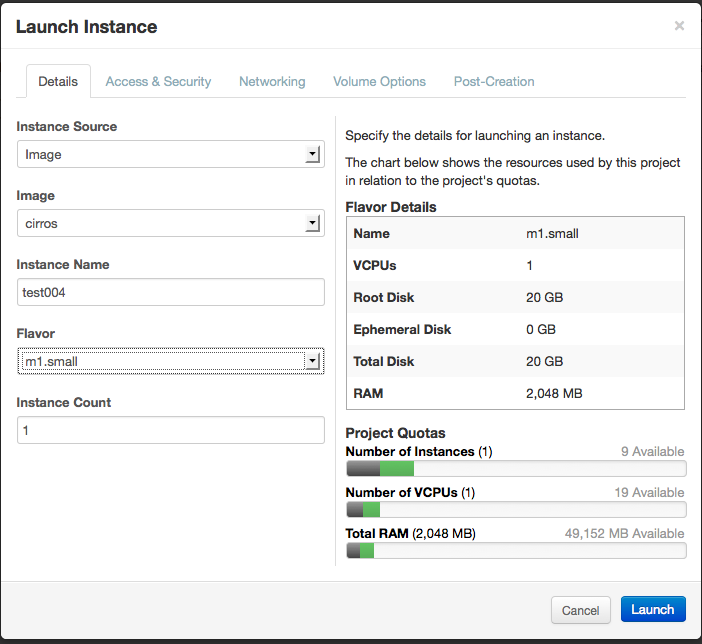
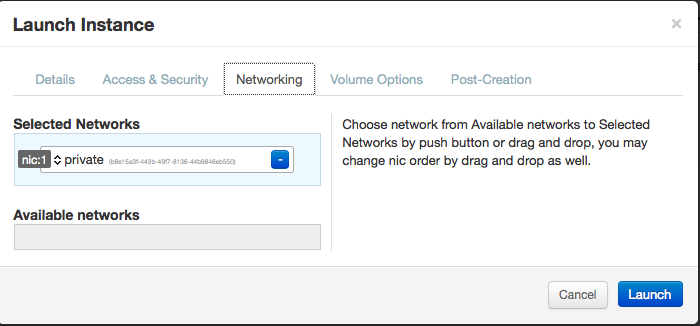
Once the instance is launched we will then associate a floating IP address with it.



Now we can ssh to it from outside the
$ ssh cirros@10.16.132.4
cirros@10.16.132.4's password:
$ uptime
00:52:20 up 14 min, 1 users, load average: 0.00, 0.00, 0.00
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Now we can get started with the fun stuff, like provisioning images from CloudForms onto RDO and using Foreman to automatically configure them!