The Problem
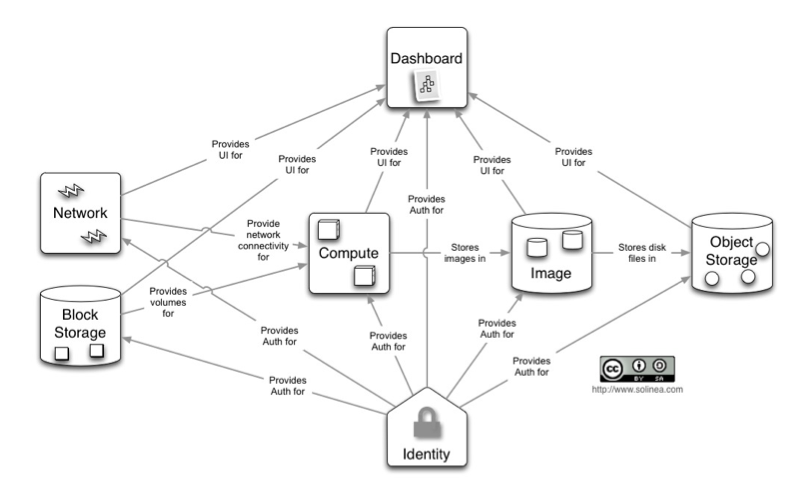
The Beauty of OpenStack
OpenStack is a thing of beauty, isn’t it? Just look at all those cleanly defined services, perfectly atomic, able to run standalone … it’s simply amazing. What more could developers and operators ask for in a cloud?
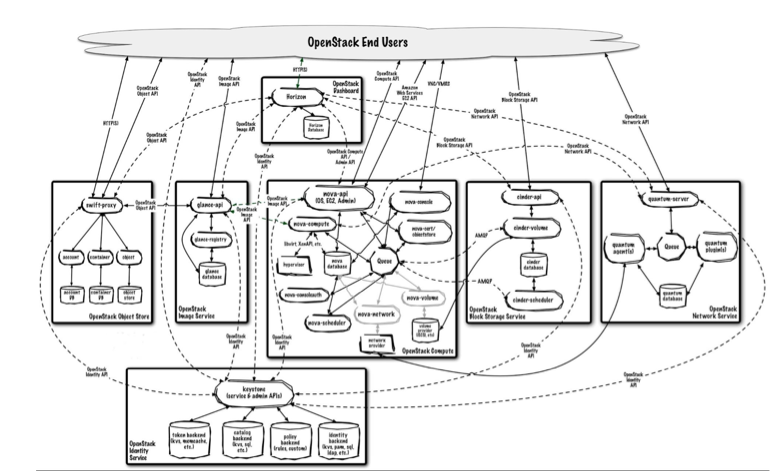
The Reality of OpenStack
Except, that it’s not exactly like that. All those services heavily rely on each other and given the rate of change OpenStack is experiencing the degree of complexity only stands to increase. The problem is that OpenStack has many services that are dependent on one another and managing the lifecycle is difficult and inefficient because of this.
Let’s look at an example of updating the keystone service, OpenStack’s identity management service. It is difficult to know whether or not deploying a new version of Keystone into an existing OpenStack deployment will cause problems because of compatibility with others services. It’s also difficult to move backwards and expensive to roll back a deployment of a new keystone service with today’s tools. Operators don’t want to use extra racks of hardware to test an upgrade of a service if they can avoid it and no lifecycle management tools that try to imperatively deploy and roll back can do so as reliability as we’d like between OpenStack releases.
At this point you might conclude that I have a personal vendetta against OpenStack. Although this could be justified after the many nights I’ve spent installing, configuring, and upgrading OpenStack I can assure you that’s not the case. In truth, OpenStack is not a beautiful and unique snowflake. Lots of different infrastructure platforms face this same problem and so do many application platforms.
The Many Paths to OpenStack Lifecycle Management
Today, there are many ways to manage the lifecycle of OpenStack services, but the two most prevalent can be loosely grouped into two categories: build based and image based deployments.
Build based lifecycle management uses a build service, such as PXE, and is typically coupled together with a bunch of lifecycle management tools and almost always uses some type of configuration management whether that’s Puppet, Chef, Ansible, or others.

This approach is generally inefficient because each OpenStack service is placed onto a different physical piece of hardware or at least a different operating system.

It is possible to combine multiple services on a single operating system, but this can get tricky. How does the lifecycle management tool know that OpenStack Service A in the image above won’t conflict with OpenStack Service B in terms of resources required, ports required, file systems, etc? It takes an awful lot of logic in a lifecycle management tool to know this and given the rate of change experienced in a community like OpenStack, lifecycle management tools have a hard time keeping up and delivering what users would like to deploy. Could virtual machines be used here? Possibly, but virtual machine are heavyweight and also lack rich metadata or require large infrastructures and agents loaded into those virtual machines to get metadata. In other words, VMs are too heavy and they also lack the concept of inheritance.

Finally, build based deployments can be slow. Copying each package back and forth over the wire is not the most efficient way of deploying at scale.
Image based deployments solve the problem of slow performance that build based systems have by not requiring each package to be installed. Typically an image based system has some sort of image building tool that stores images in a repository and these images are then streamed down to physical hardware.
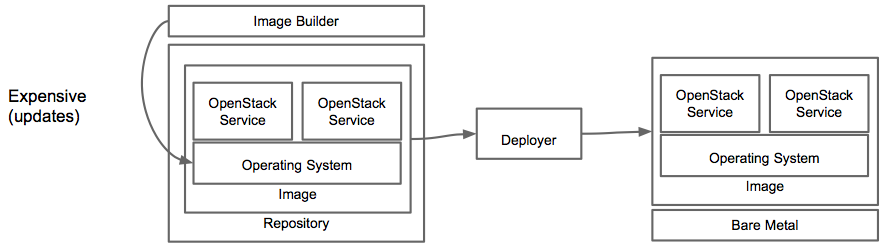
However, even while using images, incremental updates can be slow due to the large size of images. Also, the expense of pushing a large image around for small incremental updates doesn’t seem appropriate.
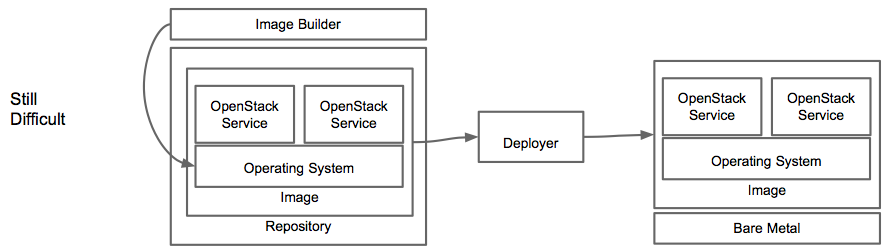
Even more importantly, image based deployments don’t solve the fundamental problem of complexity that understanding the relationships between OpenStack services presents. This problem is only moved earlier in the process and must be solved when building the images themselves instead of at run-time.
There is one other consideration that should be taken when looking at building a lifecycle management solution for OpenStack and that is that OpenStack doesn’t live alone. The last thing most operators want is yet another way to manage the lifecycle of a new platform. They’d like something that they can use across platforms from bare metal, to IaaS, and possibly even in a PaaS.
What Atomic, Docker, and Kubernetes Bring to the Party
Wouldn’t it be great if there was a solution for managing the lifecycle of Openstack services that was:
- Isolated, lightweight, Portable, and Separated
- Easily Described run-time relationships
- Could run on something thin and easy to update
- Worked to manage the lifecycle of services beyond OpenStack too
That’s exactly what the combination of Docker, Kubernetes, and Atomic can provide to the existing lifecycle management solutions.
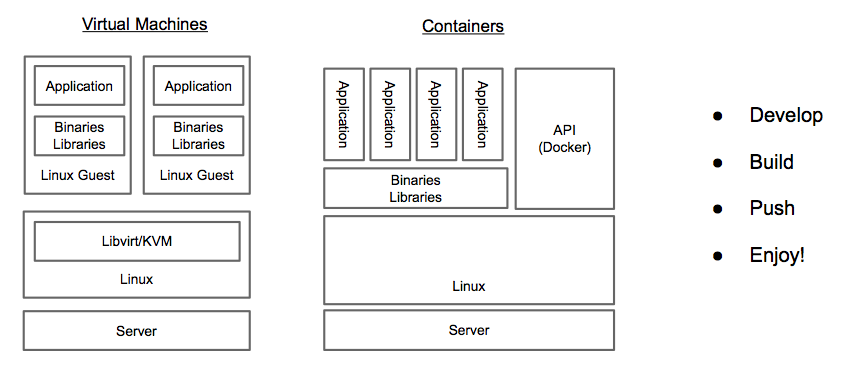
Docker provides a level of abstraction for Linux Containers through APIs and an “Engine”. It also provides an image format for sharing that supports a base and child image relationship allowing for layering. Finally, Docker provides a registry for sharing docker images. This is important because it allows developers to ship a portable image that operators can deploy on a different platform.
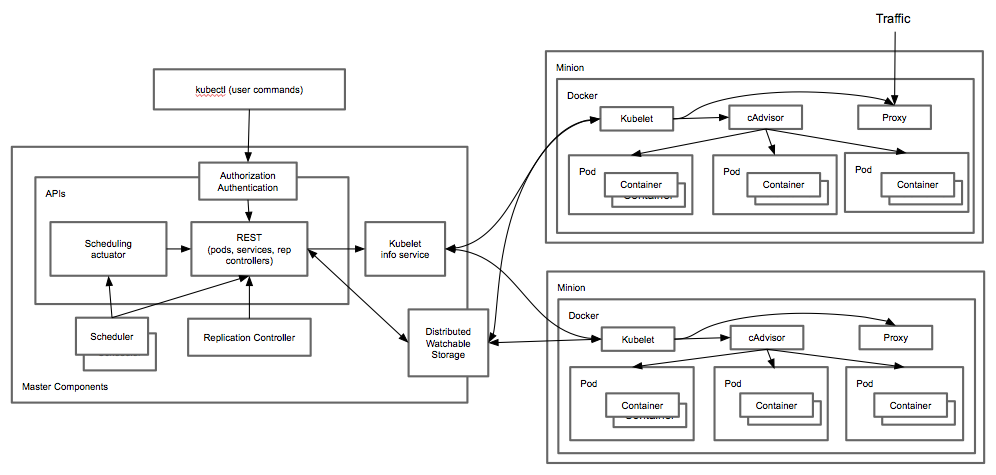
Kubernetes is an open source container cluster manager. It provides scheduling of Linux Containers using a master/minion construct. It uses a declarative syntax to express desired state. This is important because it allows developers to provide a description of the relationships between different Linux Containers and let’s the cluster manager do the scheduling.
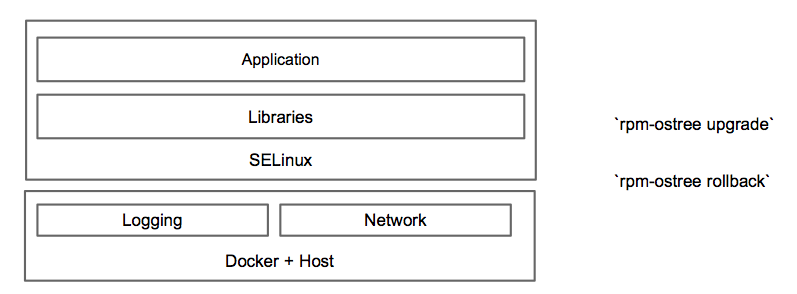
Atomic provides just enough of an operating system to run containers in a secure, stable, and high performance manner. It includes Kubernetes and Docker and allows for users to update using newly developed update mechanisms such as OSTree. Here is a quick video that shows how easy it is to deploy atomic (in this case on OpenStack) and also how easy it is to upgrade Atomic. Watch OGG
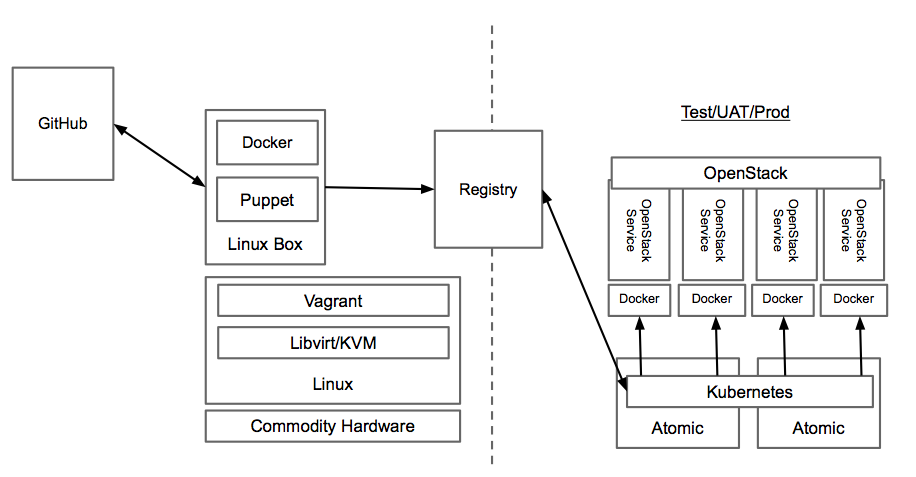
So when you put these pieces together what you end up with is something that looks (at a high level) like the diagram above. OpenStack developers are free to develop on a broad choice of platforms (Linux/Vagrant/Libvirt pictured) and can publish completed images to a registry. Operators on the other side would pull the kubernetes configurations into their lifecycle management tools and the tools would launch the pods and services. This would trigger Docker running on Atomic to pull the images locally and deploy containers with the OpenStack services. Services are isolated and (we are fairly certain given our experience with our OpenShift PaaS) lots and lots of containers could be run on a single operating system to maximize density of Openstack services. There are LOTS of other benefits including ease of rollback, deployment and update speed, etc, but this alone should be enough for anyone looking at running an OpenStack cloud at scale to be interested.
Show me the Demo!
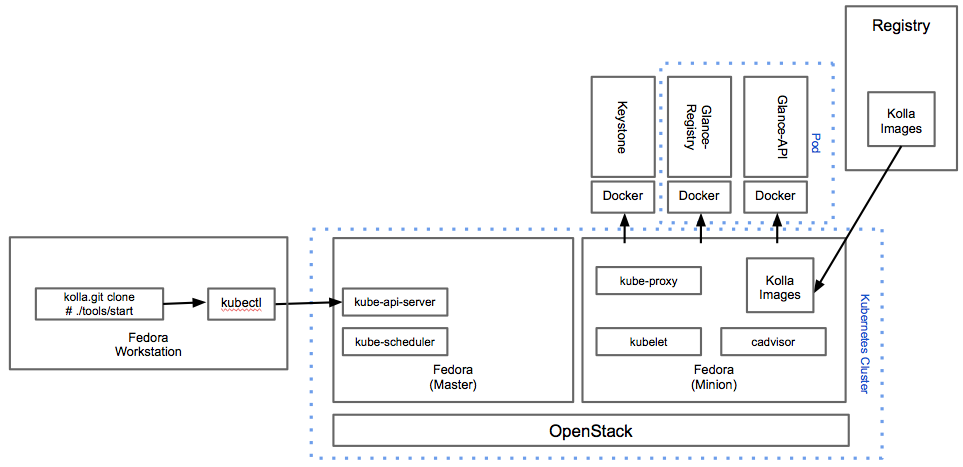
Here are several demonstrations that illustrate the scenario above. These are a demonstration of the OpenStack Kolla project and were produced in 2 weeks time by a group of amazing developers who saw the potential these technologies had.
First there is building the images and pushing them to a registry. Watch OGG
Second there is deploying a few pods and services manually to see how they connect and what Kubernetes and Docker are actually doing. Watch OGG
Finally, there is an example of deploying all the OpenStack services that were completed in milestone-1 all with a single command. Watch OGG
After deploying OpenStack countless times I can say that when you see each schema automatically created in MariaDB and endpoints, services, etc automatically created all in under a minute it is an amazing feeling!
“I’m Sold, What’s Next?”
In the end, the combination of Docker, Atomic, and Kubernetes show the promise of alleviating some of the pain OpenStack developers and operators have experienced. There are still a lot of unanswered questions, but we feel that this combination of technologies shows promise and are excited that they have found a home in the TripleO project through Kolla.
If you are interested in learning more or participating please:
- Join us for our Presentation at OpenStack Summit.
- Join the Kolla OpenStack Design Summit Session.
- Check out the Kolla project launchpad.
If you want to learn more about some of the other projects related to this post please check out the following:
- The Docker Project
- The Atomic Project
- The Kubernetes Project
- The TripleO Project
- The Foreman
