Slides from the presentation Brent Holden and I gave at OpenStack Summit can be downloaded here.
all things open
having fun with open source
A Demonstration of Kolla: Docker and Kubernetes based Deployment of OpenStack Services on Atomic
The Problem
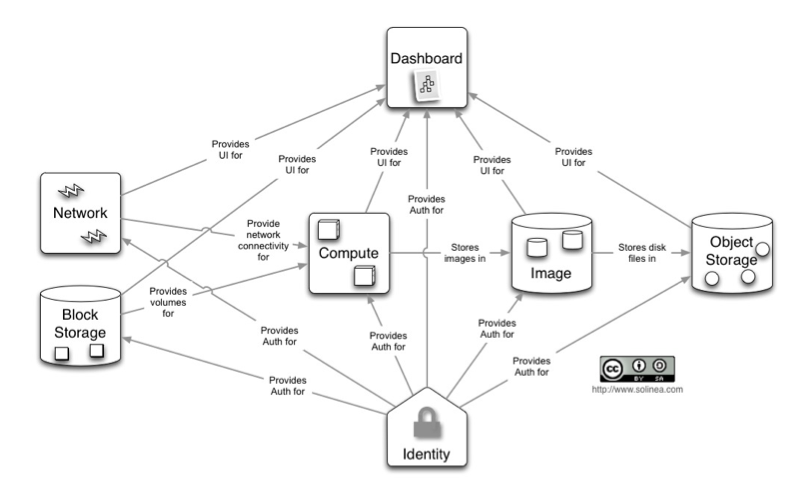
The Beauty of OpenStack
OpenStack is a thing of beauty, isn’t it? Just look at all those cleanly defined services, perfectly atomic, able to run standalone … it’s simply amazing. What more could developers and operators ask for in a cloud?
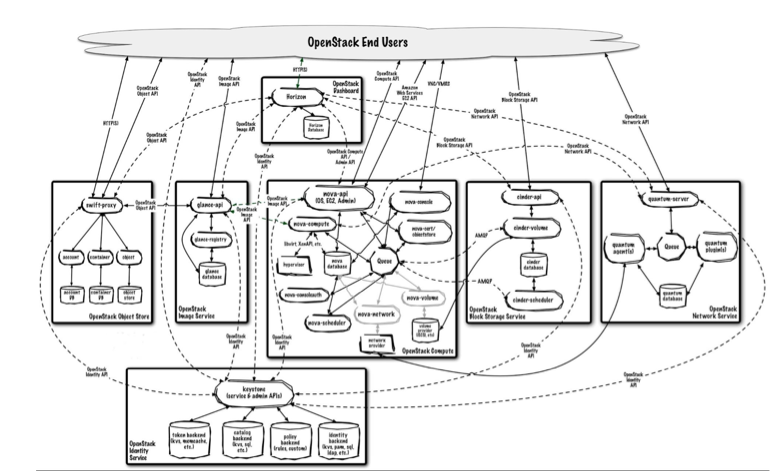
The Reality of OpenStack
Except, that it’s not exactly like that. All those services heavily rely on each other and given the rate of change OpenStack is experiencing the degree of complexity only stands to increase. The problem is that OpenStack has many services that are dependent on one another and managing the lifecycle is difficult and inefficient because of this.
Let’s look at an example of updating the keystone service, OpenStack’s identity management service. It is difficult to know whether or not deploying a new version of Keystone into an existing OpenStack deployment will cause problems because of compatibility with others services. It’s also difficult to move backwards and expensive to roll back a deployment of a new keystone service with today’s tools. Operators don’t want to use extra racks of hardware to test an upgrade of a service if they can avoid it and no lifecycle management tools that try to imperatively deploy and roll back can do so as reliability as we’d like between OpenStack releases.
At this point you might conclude that I have a personal vendetta against OpenStack. Although this could be justified after the many nights I’ve spent installing, configuring, and upgrading OpenStack I can assure you that’s not the case. In truth, OpenStack is not a beautiful and unique snowflake. Lots of different infrastructure platforms face this same problem and so do many application platforms.
The Many Paths to OpenStack Lifecycle Management
Today, there are many ways to manage the lifecycle of OpenStack services, but the two most prevalent can be loosely grouped into two categories: build based and image based deployments.
Build based lifecycle management uses a build service, such as PXE, and is typically coupled together with a bunch of lifecycle management tools and almost always uses some type of configuration management whether that’s Puppet, Chef, Ansible, or others.

This approach is generally inefficient because each OpenStack service is placed onto a different physical piece of hardware or at least a different operating system.

It is possible to combine multiple services on a single operating system, but this can get tricky. How does the lifecycle management tool know that OpenStack Service A in the image above won’t conflict with OpenStack Service B in terms of resources required, ports required, file systems, etc? It takes an awful lot of logic in a lifecycle management tool to know this and given the rate of change experienced in a community like OpenStack, lifecycle management tools have a hard time keeping up and delivering what users would like to deploy. Could virtual machines be used here? Possibly, but virtual machine are heavyweight and also lack rich metadata or require large infrastructures and agents loaded into those virtual machines to get metadata. In other words, VMs are too heavy and they also lack the concept of inheritance.

Finally, build based deployments can be slow. Copying each package back and forth over the wire is not the most efficient way of deploying at scale.
Image based deployments solve the problem of slow performance that build based systems have by not requiring each package to be installed. Typically an image based system has some sort of image building tool that stores images in a repository and these images are then streamed down to physical hardware.
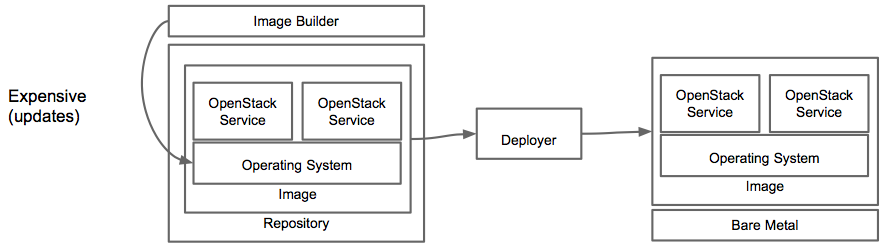
However, even while using images, incremental updates can be slow due to the large size of images. Also, the expense of pushing a large image around for small incremental updates doesn’t seem appropriate.
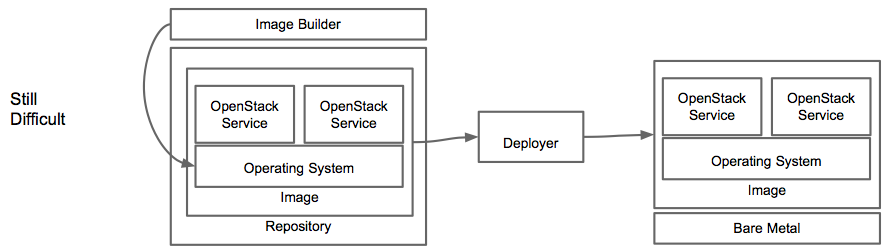
Even more importantly, image based deployments don’t solve the fundamental problem of complexity that understanding the relationships between OpenStack services presents. This problem is only moved earlier in the process and must be solved when building the images themselves instead of at run-time.
There is one other consideration that should be taken when looking at building a lifecycle management solution for OpenStack and that is that OpenStack doesn’t live alone. The last thing most operators want is yet another way to manage the lifecycle of a new platform. They’d like something that they can use across platforms from bare metal, to IaaS, and possibly even in a PaaS.
What Atomic, Docker, and Kubernetes Bring to the Party
Wouldn’t it be great if there was a solution for managing the lifecycle of Openstack services that was:
- Isolated, lightweight, Portable, and Separated
- Easily Described run-time relationships
- Could run on something thin and easy to update
- Worked to manage the lifecycle of services beyond OpenStack too
That’s exactly what the combination of Docker, Kubernetes, and Atomic can provide to the existing lifecycle management solutions.
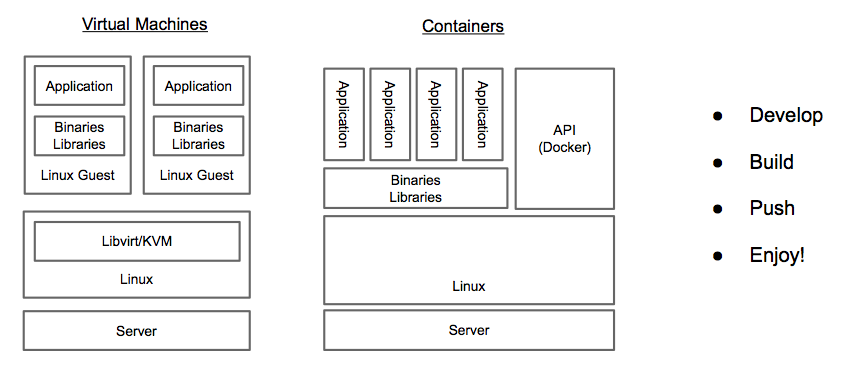
Docker provides a level of abstraction for Linux Containers through APIs and an “Engine”. It also provides an image format for sharing that supports a base and child image relationship allowing for layering. Finally, Docker provides a registry for sharing docker images. This is important because it allows developers to ship a portable image that operators can deploy on a different platform.
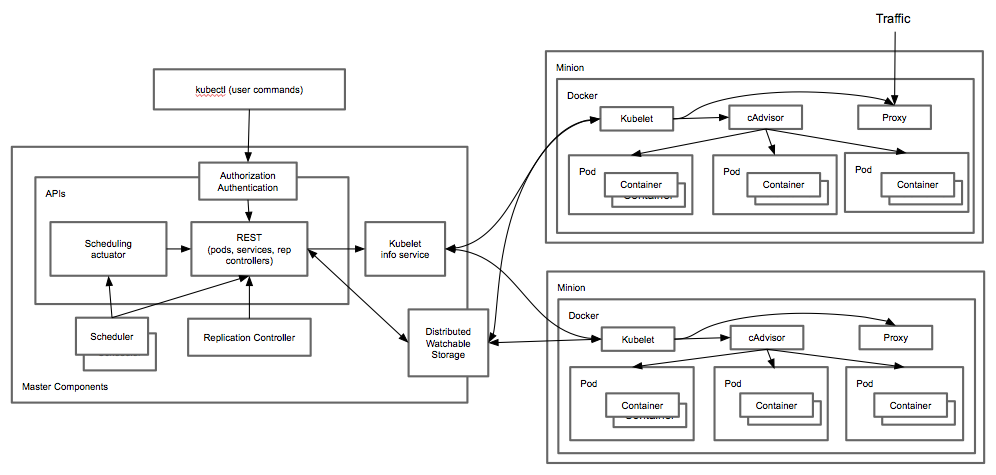
Kubernetes is an open source container cluster manager. It provides scheduling of Linux Containers using a master/minion construct. It uses a declarative syntax to express desired state. This is important because it allows developers to provide a description of the relationships between different Linux Containers and let’s the cluster manager do the scheduling.
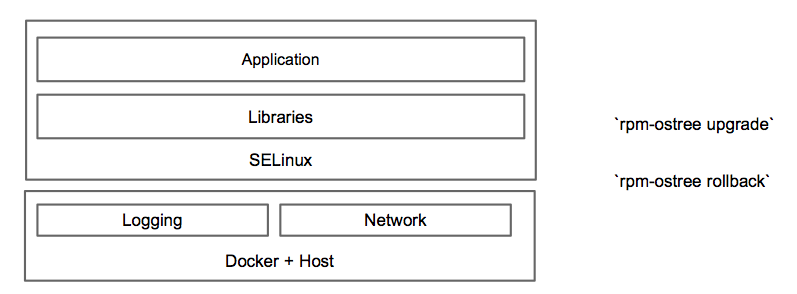
Atomic provides just enough of an operating system to run containers in a secure, stable, and high performance manner. It includes Kubernetes and Docker and allows for users to update using newly developed update mechanisms such as OSTree. Here is a quick video that shows how easy it is to deploy atomic (in this case on OpenStack) and also how easy it is to upgrade Atomic. Watch OGG
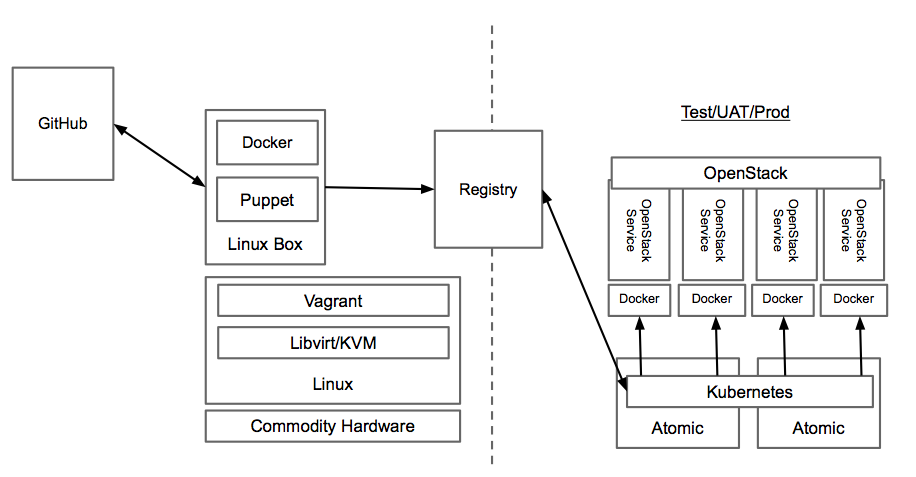
So when you put these pieces together what you end up with is something that looks (at a high level) like the diagram above. OpenStack developers are free to develop on a broad choice of platforms (Linux/Vagrant/Libvirt pictured) and can publish completed images to a registry. Operators on the other side would pull the kubernetes configurations into their lifecycle management tools and the tools would launch the pods and services. This would trigger Docker running on Atomic to pull the images locally and deploy containers with the OpenStack services. Services are isolated and (we are fairly certain given our experience with our OpenShift PaaS) lots and lots of containers could be run on a single operating system to maximize density of Openstack services. There are LOTS of other benefits including ease of rollback, deployment and update speed, etc, but this alone should be enough for anyone looking at running an OpenStack cloud at scale to be interested.
Show me the Demo!
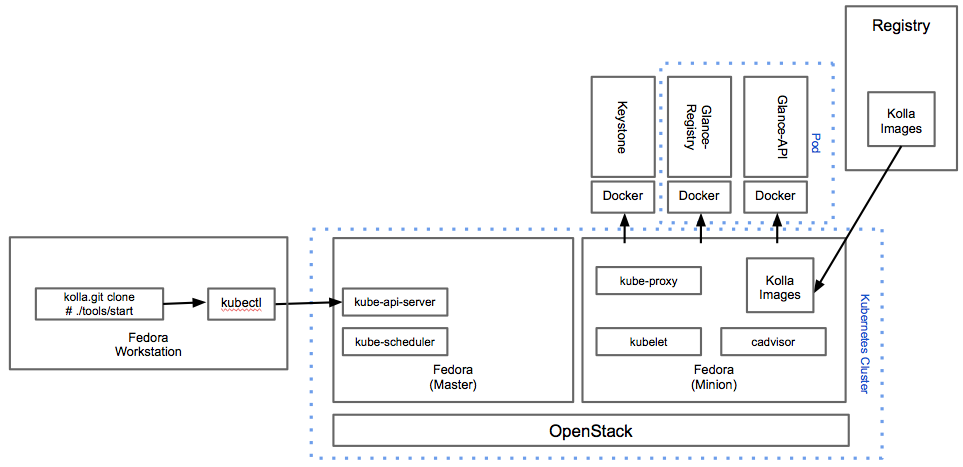
Here are several demonstrations that illustrate the scenario above. These are a demonstration of the OpenStack Kolla project and were produced in 2 weeks time by a group of amazing developers who saw the potential these technologies had.
First there is building the images and pushing them to a registry. Watch OGG
Second there is deploying a few pods and services manually to see how they connect and what Kubernetes and Docker are actually doing. Watch OGG
Finally, there is an example of deploying all the OpenStack services that were completed in milestone-1 all with a single command. Watch OGG
After deploying OpenStack countless times I can say that when you see each schema automatically created in MariaDB and endpoints, services, etc automatically created all in under a minute it is an amazing feeling!
“I’m Sold, What’s Next?”
In the end, the combination of Docker, Atomic, and Kubernetes show the promise of alleviating some of the pain OpenStack developers and operators have experienced. There are still a lot of unanswered questions, but we feel that this combination of technologies shows promise and are excited that they have found a home in the TripleO project through Kolla.
If you are interested in learning more or participating please:
- Join us for our Presentation at OpenStack Summit.
- Join the Kolla OpenStack Design Summit Session.
- Check out the Kolla project launchpad.
If you want to learn more about some of the other projects related to this post please check out the following:
- The Docker Project
- The Atomic Project
- The Kubernetes Project
- The TripleO Project
- The Foreman
Docker All The Things – OpenStack Keystone and Ceilometer Automated Builds on Docker Hub
Ok, I borrowed part of the title of this post from Nicola Paolucci at Atlassian’s blog post who likely borrowed it from a bunch of others, but it was just too good to pass up.
I decided to test Docker Hub’s automated build feature to see if I could have automated docker images created from a project relevant to Red Hat Cloud Infrastructure (RHCI), Red Hat’s private IaaS cloud solution. RHCI combines datacenter virtualization based on Red Hat Enterprise Virtualization (RHEV), scale out IaaS based on Red Hat Enterprise Linux OpenStack Platform (RHELOSP), and cloud management based on CloudForms. These come from the upstream communities of oVirt, OpenStack, and ManageIQ.
If you are interested in why containers could be so beneficial to an Infrastructure as a Service solution you could read my previous post, “Why containers for OpenStack Services?”. The bottom line is that moving more logic about the lifecycle of the IaaS services into the application layer (Think PaaS for IaaS) could solve many problems and help IaaS become much easier to manage.
Keystone Docker Image
The natural choice for the first service to attempt to containerize was the identity service, Keystone. Keystone has (relative to other openstack projects) few moving parts and is also required by most of the other services since it publishes a catalog of endpoints for the other services APIs.
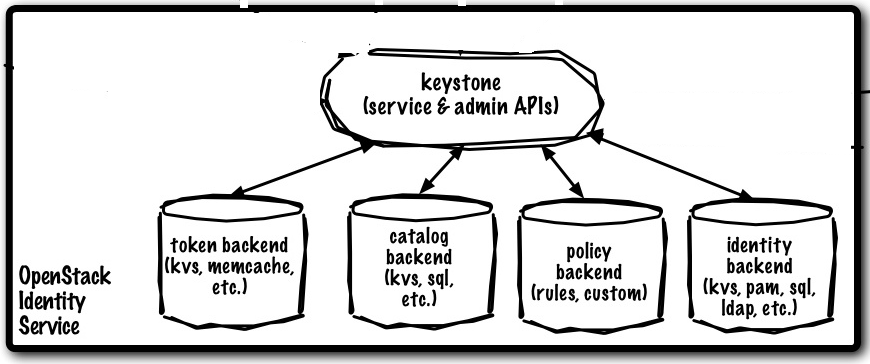
Here is what I did:
1. I forked the openstack keystone project.
2. I created a new automated build on Docker Hub.
3. I cloned the git repository for my fork of keystone.
jlabocki@localhost# git clone https://github.com/jameslabocki/keystone.git
Cloning into 'keystone'...
remote: Counting objects: 26085, done.
remote: Compressing objects: 100% (9122/9112), done.
remote: Total 26085 (delta 16076), reused 26085 (delta 16076)
Receiving objects: 100% (1285/1285), 5.61 MiB | 2.14 MiB/s, done.
Resolving deltas: 100% (176/176), done.
Checking connectivity... done.
4. I created a Dockerfile in the root of the cloned keystone repository. Here is the contents of the Dockerfile.
FROM fedora
MAINTAINER jlabocki@redhat.com
# This Dockerfile installs the components of Keystone in a docker image as a proof of concept
#Timestamps are always useful
RUN date > /root/date
#Install required packages
RUN yum install python-pbr git python-devel python-setuptools python-pip gcc gcc-devel libxml2-python libxslt-python python-lxml sqlite python-repoze-lru -y
#RUN yum install python-sqlite2 python-lxml python-greenlet-devel python-ldap sqlite-devel openldap-devel -y
#Clone Keystone and setup
WORKDIR /opt
RUN git clone http://github.com/openstack/keystone.git
WORKDIR /opt/keystone
RUN python setup.py install
#Configure Keystone
RUN mkdir -p /etc/keystone
RUN cp etc/keystone.conf.sample /etc/keystone/keystone.conf
RUN cp etc/keystone-paste.ini /etc/keystone/
RUN sed -ri 's/#driver=keystone.identity.backends.sql.Identity/driver=keystone.identity.backends.sql.Identity/' /etc/keystone/keystone.conf
RUN sed -ri 's/#connection=<None>/connection=sqlite:\/\/\/keystone.db/' /etc/keystone/keystone.conf
RUN sed -ri 's/#idle_timeout=3600/idle_timeout=200/' /etc/keystone/keystone.conf
RUN sed -ri 's/#admin_token=ADMIN/admin_token=ADMIN/' /etc/keystone/keystone.conf
# The following sections build a script that will be executed on launch via ENTRYPOINT
## Start Keystone
RUN echo "#!/bin/bash" > /root/postlaunchconfig.sh
RUN echo "/usr/bin/keystone-manage db_sync" >> /root/postlaunchconfig.sh
RUN echo "/usr/bin/keystone-all &" >> /root/postlaunchconfig.sh
## Create Services
#I'm not sure if exporting works, so I just specify these environment variables on each command, but it might be cleaner to test this
#RUN export OS_SERVICE_ENDPOINT=http://localhost:35357/v2.0
#RUN export OS_SERVICE_TOKEN=ADMIN
#RUN export OS_AUTH_URL=http://127.0.0.1:35357/v2.0/
RUN echo '/usr/bin/keystone --os_auth_url http://127.0.0.1:35357/v2.0/ --os-token ADMIN --os-endpoint http://127.0.0.1:35357/v2.0/ service-create --name=ceilometer --type=metering --description="Ceilometer Service"' >> /root/postlaunchconfig.sh
RUN echo '/usr/bin/keystone --os_auth_url http://127.0.0.1:35357/v2.0/ --os-token ADMIN --os-endpoint http://127.0.0.1:35357/v2.0/ service-create --name=keystone --type=identity --description="OpenStack Identity"' >> /root/postlaunchconfig.sh
RUN chmod 755 /root/postlaunchconfig.sh
#This you will need to substitute your values and run later - the values are:
# CEILOMETER_SERVICE = the id of the service created by the keystone service-create command
# KEYSTONE_SERVICE = the id of the service created by the keystone service-create command
# CEILOMETER_SERVICE_HOST = the host where the Ceilometer API is running
# KEYSTONE_SERVICE_HOST = the host where the Keystone API is running
RUN echo 'keystone --os_auth_url http://127.0.0.1:35357/v2.0/ --os-token ADMIN --os-endpoint http://127.0.0.1:35357/v2.0/ endpoint-create --region RegionOne --service_id $KEYSTONE_SERVER --publicurl "http://KEYSTONE_SERVICE_HOST:5000/v2.0" --internalurl "http://KEYSTONE_SERVICE_HOST:5000/v2.0" --adminurl "http://KEYSTONE_SERVICE_HOST:35357/v2.0"' > /root/postlaunchconfig.sh
RUN echo 'keystone --os_auth_url http://127.0.0.1:35357/v2.0/ --os-token ADMIN --os-endpoint http://127.0.0.1:35357/v2.0/ endpoint-create --region RegionOne --service_id $CEILOMETER_SERVICE --publicurl "http://CEILOMETER_SERVICE_HOST:8777/" --adminurl "http://CEILOMETER_SERVICE_HOST:8777/" --internalurl "http://CEILOMETER_SERVICE_HOST:8777/"' > /root/postlaunchconfig.sh
5. I committed and pushed the change.
[root@localhost keystone]# git commit -m "testing" .
[master fe12eff] testing
1 file changed, 6 insertions(+), 7 deletions(-)
[root@localhost keystone]# git push
Username for 'https://github.com':@.com
Password for 'https://@github.com':
Counting objects: 14, done.
Delta compression using up to 2 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 335 bytes | 0 bytes/s, done.
Total 3 (delta 2), reused 0 (delta 0)
To https://github.com/jameslabocki/keystone.git
a3de5a2..fe12eff master -> master
6. The automated build finished successfully.
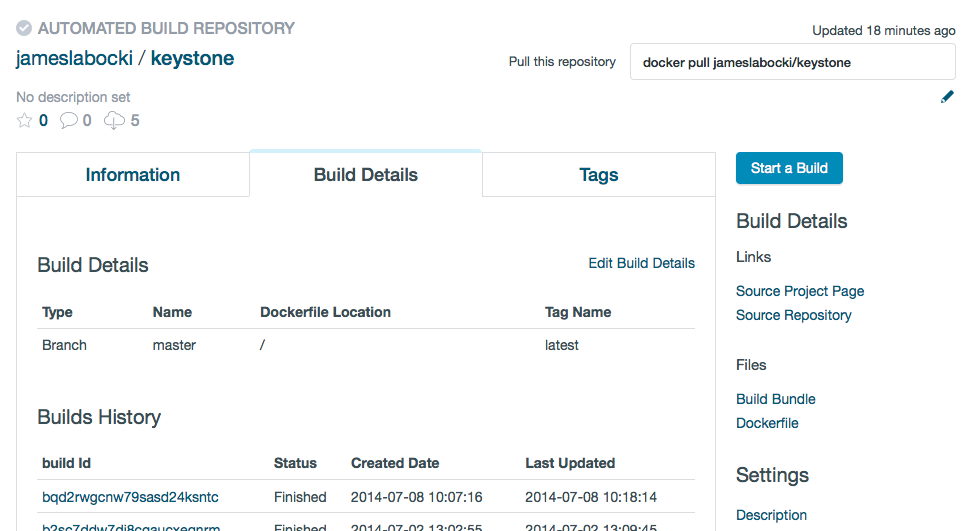
7. I could check the details of the build, including the Dockerfile used and the output of the build.
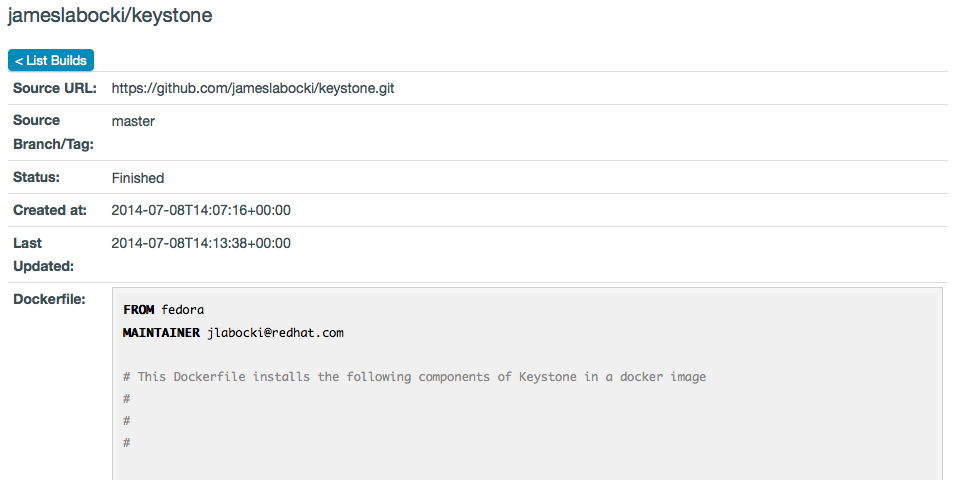
Assuming that the image was good and I could run it and setup Keystone rather quickly I decided to focus on another service and then attempt launching the two together (see the results section if you want to spoil the surprise).
Ceilometer Docker Image
I selected the OpenStack telemetry project, commonly known as Ceilometer, for my next test of an automated build of a docker image to take place on commit to my forked repository. Why Ceilometer? After looking at the OpenStack architecture diagram I thought it might be one of the easier services to run in a container (basically, I used a dart board), and since it only requires keystone I thought I might be able to make it happen next. Here are the components of OpenStack Ceilometer (Telemetry) at a glance taken from the OpenStack docs.
The telemetry system consists of the following basic components:
- A compute agent (ceilometer-agent-compute). Runs on each compute node and polls for resource utilization statistics. There may be other types of agents in the future, but for now we will focus on creating the compute agent.
- A central agent (ceilometer-agent-central). Runs on a central management server to poll for resource utilization statistics for resources not tied to instances or compute nodes.
- A collector (ceilometer-collector). Runs on one or more central management servers to monitor the message queues (for notifications and for metering data coming from the agent). Notification messages are processed and turned into metering messages and sent back out onto the message bus using the appropriate topic. Telemetry messages are written to the data store without modification.
- An alarm notifier (ceilometer-alarm-notifier). Runs on one or more central management servers to allow settting alarms based on threshold evaluation for a collection of samples.
- A data store. A database capable of handling concurrent writes (from one or more collector instances) and reads (from the API server).
- An API server (ceilometer-api). Runs on one or more central management servers to provide access to the data from the data store. These services communicate using the standard OpenStack messaging bus. Only the collector and API server have access to the data store.
Here it is in a diagram.

I decided to start with the database and ceilometer collector and then add the API. I went the route of placing all of these services in a single image. I’m aware there is a lot of debate as to whether Docker images should only run a single process or if multiple processes could be beneficial. My intention wasn’t to optimize the image for production, rather it was to test how easy or difficult it was to take a forked GitHub project and get it into an image build in an automated fashion that I could run on my Fedora 20 workstation. Also, I did not plan to add the evaluator, notifier, or any agents to this image. Since most of the agents require other components of OpenStack.
Here is what I did:
1. I forked the openstack ceilometer project.

2. I created another new automated build on Docker Hub.
3. I cloned the git repository for my fork of ceilometer.
jlabocki@localhost# git clone https://github.com/jameslabocki/ceilometer.git
Cloning into ‘ceilometer’…
remote: Counting objects: 26085, done.
remote: Compressing objects: 100% (7112/7112), done.
remote: Total 26085 (delta 16076), reused 26085 (delta 16076)
Receiving objects: 100% (26085/26085), 8.81 MiB | 3.14 MiB/s, done.
Resolving deltas: 100% (16076/16076), done.
Checking connectivity… done.
4. I created a Dockerfile in the root of the project following the manual installation of OpenStack Ceilometer. Here is the contents of the Dockerfile. Note I wasn’t able to run the mongod command during the build successfully. More on that later, I just created a post launch script that could be executed after the docker image is launched as a work around.
FROM fedora
MAINTAINER jlabocki@redhat.com
# This Dockerfile installs some of the components of Ceilometer in a Docker Image as a proof of concept
#
#Timestamps are always useful
RUN date > /root/date
#Install required packages
RUN yum install mysql-devel openssl-devel wget unzip git mongodb mongodb-server python-devel mysql-server libmysqlclient-devel libffi-devel libxml2-devel libxslt-devel python-setuptools python-pip libffi libffi-devel gcc gcc-devel python-pip python-pbr mongodb python-pymongo rabbitmq-server -y
#RUN pip install tox
#Can't run the line above because https://bugs.launchpad.net/openstack-ci/+bug/1274135, need to specify version 1.6.1
RUN pip install tox==1.6.1
#MongoDB Setup
RUN mkdir -p /data/db
RUN echo 'db.addUser("admin", "insecure", true);' > /root/mongosetup.js
#RabbitMQ Setup
RUN /usr/sbin/rabbitmq-server -detached
#Clone Ceilometer
RUN git clone https://github.com/jlabocki/ceilometer.git /opt/stack/
#Ceilometer Collector Configuration
WORKDIR /opt/stack
RUN python setup.py install
RUN mkdir -p /etc/ceilometer
RUN tox -egenconfig
RUN cp /opt/stack/etc/ceilometer/*.json /etc/ceilometer
RUN cp /opt/stack/etc/ceilometer/*.yaml /etc/ceilometer
RUN cp /opt/stack/etc/ceilometer/ceilometer.conf.sample /etc/ceilometer/ceilometer.conf
#Ceilometer Collector Configuration changes
RUN sed -ri 's/#metering_secret=change this or be hacked/metering_secret=redhat/' /etc/ceilometer/ceilometer.conf
RUN sed -ri 's/#connection=<None>/connection = mongodb:\/\/admin:insecure@localhost:27017\/ceilometer/' /etc/ceilometer/ceilometer.conf
#Ceilometer API Configuration changes
RUN cp etc/ceilometer/api_paste.ini /etc/ceilometer/api_paste.ini
##Ceilometer Post Launch Configuration
RUN echo "#!/bin/bash" > /root/postlaunch.sh
#Add Authenticate against keystone to the post launch script
# KEYSTONE_HOST = the keystone host
RUN echo "sed -ri 's/#identity_uri=<None>/identity_uri=KEYSTONE_HOST/' /etc/ceilometer/ceilometer.conf" >> /root/postlaunch.sh
#Add starting services to the postlaunch script
RUN echo "/bin/mongod --dbpath /data/db --fork --logpath /root/mongo.log --noprealloc --smallfiles" >> /root/postlaunch.sh
RUN echo "/bin/mongo mydb /root/mongosetup.js" >> /root/postlaunch.sh
RUN echo "/usr/bin/ceilometer-collector" >> /root/postlaunch.sh
RUN echo "/usr/bin/ceilometer-api" >> /root/postlaunch.sh
RUN chmod 755 /root/postlaunch.sh5. I added and committed the change and pushed.
[root@localhost ceilometer]# git commit -m "testing" .
[master fe12eff] testing
1 file changed, 6 insertions(+), 7 deletions(-)
[root@localhost keystone]# git push
Username for 'https://github.com':@.com
Password for 'https://@github.com':
Counting objects: 14, done.
Delta compression using up to 2 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 335 bytes | 0 bytes/s, done.
Total 3 (delta 2), reused 0 (delta 0)
To https://github.com/jameslabocki/ceilometer.git
a3de5a2..fe12eff master -> master
6. The automated build finished successfully.
7. I was again able to view the Dockerfile and the output of the docker build.
The Results
Voila! The automated build in Docker Hub triggers builds each time I push a change to GitHub and my images were now ready to be pulled down. Here is the pull…
[jameslabocki@localhost ~]$ docker pull jameslabocki/ceilometer
Pulling repository jameslabocki/ceilometer
c6f1a8880f25: Download complete
511136ea3c5a: Download complete
fd241224e9cf: Download complete
3f2fed40e4b0: Download complete
dba879135119: Download complete
18e0ba2cede2: Download complete
f95adbc11b72: Download complete
0816f2338632: Download complete
9d5ab1dabbc6: Download complete
b9699e746fd1: Download complete
f5089b261315: Download complete
16ddaee924ac: Download complete
aa364c587e7f: Download complete
c33d108a2ed1: Download complete
a131665ee3cb: Download complete
de2e2481c394: Download complete
220014c6f68a: Download complete
291a7a267101: Download complete
e2394bfd4a3f: Download complete
6f3c660adc44: Download complete
7e32f4d4b9b3: Download complete
48eb2ed1f711: Download complete
4bdd06d07972: Download complete
e3299cecd69d: Download complete
c6ccb763dee0: Download complete
2c2de8d95775: Download complete
5d6699390133: Download complete
c6b60ee39aa4: Download complete
[jameslabocki@localhost ~]$ docker pull jameslabocki/keystone
Pulling repository jameslabocki/keystone
2653e44d0420: Download complete
511136ea3c5a: Download complete
fd241224e9cf: Download complete
3f2fed40e4b0: Download complete
ba543dd23e14: Download complete
64f9a0c3a01e: Download complete
89475c70d6b2: Download complete
541ad4ae8739: Download complete
7497b01e4a38: Download complete
68eb2b0e770d: Download complete
a5b4e9a6299c: Download complete
69804e70b9be: Download complete
061825f3a29d: Download complete
f2789b8735b4: Download complete
f25b5709610e: Download complete
133b65e73ad2: Download complete
34152ccfe1a0: Download complete
334d431c2297: Download complete
b0c278d16459: Download complete
8b4eb357e27b: Download complete
85d002913148: Download complete
a0ff34bfbe61: Download complete
e2f611facb89: Download complete
92335c389d86: Download complete
0dd39fdaf260: Download complete
I can also run them and in relatively short order have keystone and ceilometer running side by side on the same host. These containers are relatively isolated, much smaller then virtual machines, and I don’t have to worry about my local machine getting foobar’d while working on keystone or ceilometer. Some great benefits to developers and (eventually) to ops teams.
[jameslabocki@localhost ~]$ sudo docker run -i -t jameslabocki/keystone /bin/bash
On the keystone container I can execute each of the steps in /root/postlaunchconfig.sh one by one to get keystone up and running and create the services and endpoints.
bash-4.2# /usr/bin/keystone-manage db_sync
bash-4.2# /usr/bin/keystone-all &
bash-4.2# /usr/bin/keystone-manage pki_setup --keystone-user root --keystone-group root
2014-07-10 02:12:47.284 413 WARNING keystone.cli [-] keystone-manage pki_setup is not recommended for production use.
Generating RSA private key, 2048 bit long modulus
..........+++
...............................................................+++
e is 65537 (0x10001)
Generating RSA private key, 2048 bit long modulus
............................................................................................+++
......................................................................+++
e is 65537 (0x10001)
Using configuration from /etc/keystone/ssl/certs/openssl.conf
Check that the request matches the signature
Signature ok
The Subject's Distinguished Name is as follows
countryName :PRINTABLE:'US'
stateOrProvinceName :ASN.1 12:'Unset'
localityName :ASN.1 12:'Unset'
organizationName :ASN.1 12:'Unset'
commonName :ASN.1 12:'www.example.com'
Certificate is to be certified until Jul 7 02:12:47 2024 GMT (3650 days)
Write out database with 1 new entries
Data Base Updated
bash-4.2# /usr/bin/keystone –os_auth_url http://127.0.0.1:35357/v2.0/ –os-token ADMIN –os-endpoint http://127.0.0.1:35357/v2.0/ service-create –name=ceilometer –type=metering –description=”Ceilometer Service”
WARNING: Bypassing authentication using a token & endpoint (authentication credentials are being ignored).
+————-+———————————-+
| Property | Value |
+————-+———————————-+
| description | Ceilometer Service |
| enabled | True |
| id | 27b508729fd84be7994846873b6d7ab2 |
| name | ceilometer |
| type | metering |
+————-+———————————-+
bash-4.2# /usr/bin/keystone –os_auth_url http://127.0.0.1:35357/v2.0/ –os-token ADMIN –os-endpoint http://127.0.0.1:35357/v2.0/ service-create –name=keystone –type=identity –description=”OpenStack Identity”
WARNING: Bypassing authentication using a token & endpoint (authentication credentials are being ignored).
+————-+———————————-+
| Property | Value |
+————-+———————————-+
| description | OpenStack Identity |
| enabled | True |
| id | 8ccd55d9d6e04b5ca768a033e61db1a1 |
| name | keystone |
| type | identity |
+————-+———————————-+
Unfortunately, while I’m able to get tokens as a user that I created I’m not able to list users, so I am stuck. I think this might be a bug on the master branch and I’ll be digging into it.
Now, on to Ceilometer …
[jameslabocki@localhost ~]$ sudo docker run -i -t jameslabocki/ceilometer /bin/bash
bash-4.2# sed -ri 's/#identity_uri=<None>/identity_uri=https://172.17.0.3:35357/' /etc/ceilometer/ceilometer.conf
bash-4.2# /bin/mongod --dbpath /data/db --fork --logpath /root/mongo.log --noprealloc --smallfiles
note: noprealloc may hurt performance in many applications
about to fork child process, waiting until server is ready for connections.
forked process: 14
all output going to: /root/mongo.log
child process started successfully, parent exiting
bash-4.2# /bin/mongo ceilometer /root/mongosetup.js
MongoDB shell version: 2.4.6
connecting to: ceilometer
{
"user" : "admin",
"readOnly" : true,
"pwd" : "46553e9fc2cdeada18e714cedbd05c9e",
"_id" : ObjectId("53bdff272da99d751819ff1d")
}
bash-4.2# /usr/bin/ceilometer-collector &
[1] 162
bash-4.2# /usr/bin/ceilometer-api &
[1] 192
I also had one more issue that I needed to work around since I was running from trunk. I had to patch a file to work around a relative pathing issue with the ceilometer API – https://review.openstack.org/#/c/99599/2/ceilometer/api/app.py
Since the keystone service was having issues I wasn’t able to run ceilometer meter-list or other commands (yet), but I do have the processes running in containers. I’ll continue to troubleshoot the keystone issue to see if I can tie these two services together.
Observations
A few thoughts came to mind while running through this exercise.
1. An area that would benefit from tooling is the ability to take an existing docker image and determine how it could be re-based on an existing parent image. For example, after I went through installing python, python-devel, mysql-devel, etc it would be nice if Docker Hub or another tool could tell me that I could save time on builds by using a parent image that already contained those components (no need to `RUN docker yum install` anything). This would save time during build processes. Call it deduplication for Docker!
2. If build times could be kept really short with such tooling it would be REALLY cool to attach an IDE to Docker Hub so that as you typed code into a project on GitHub you could instantly find out the build status. Of course syntax checking could solve some problems in a Dockerfile, but I am thinking along the lines of launching multiple docker builds and testing them with real data (system, UAT, or performance testing scenarios) and returning the result in near real-time. Building a truly integrated development experience into a continuous delivery pipeline could be really powerful (I’m imagining an IDE showing you that the line you just wrote caused a failure when run with 3-4 other docker image builds and launched on AWS, GCE, etc or that the performance was degraded).
3. Extending docker files to have pre-requisites on other docker images would allow users to reference other images required. For example, instead of installing MongoDB on the same docker image it would have been nice to be able to put some statements like this in the Dockerfile.
REFERENCE MONGODB=`docker pull mongo`
sed -ri ‘s/#connection=/connection=${MONGODB:IP_ADDR}/’
Perhaps this should live outside the Dockerfile in systemd, geard, heat, or some configuration language (puppet) and orchestration engine (Kubernetes). Whatever the case, once Docker Hub and other automated Docker build services have this functionality building images that depend on other services will be very powerful.
4. Some of the commands, such as running mongod and then adding a user during the docker hub build kept failing. I’m not sure if I am missing something, but it would seem that being able to run mongod during the build process to add users or seed data into the docker image is something that would be useful. Local docker builds also failed at this. Again, this might be something I am doing incorrectly.
One thing is certain in my mind, the future is bright for containerized IaaS services and sooner or later PaaS will drive the lifecycle of IaaS private cloud services and make the life of Ops much easier!
Here is a link to my docker hub builds for ceilometer and keystone if you want to look further.
Satellite 6
Satellite 6 Slides from the Red Hat Tech Exchange can be downloaded here
OpenStack Foreman Installer
OpenStack Foreman Installer Slides from the Red Hat Tech Exchange can be downloaded here.
Red Hat Cloud Infrastructure Update and Roadmap Slides
Red Hat Cloud Infrastructure Update and Roadmap Slides from the Red Hat Tech Exchange can be downloaded here.
Datacenter to Cloud
Slides for the Datacenter to Cloud Keynote at the Red Hat Tech Exchange can be downloaded here.
Why Containers for OpenStack Services?
An interesting problem to solve in OpenStack is the management of OpenStack’s services. Whether it’s at the time of provisioning or updating, the OpenStack services could listen on similar ports and require modification of common configuration files.
Because of this, the services could potentially conflict with one another if deployed on the same system. For example, the network service may attempt to listen on the same port as the identity service or the compute service may edit a file that the network service expects to have different values. How do you deal with this problem, particularly when each OpenStack project has a tendency to work as an independent project? It doesn’t seem likely that it would be easy to drive consensus between the various projects on ports to listen on, configuration files to modify – particularly with the speed that OpenStack is moving.
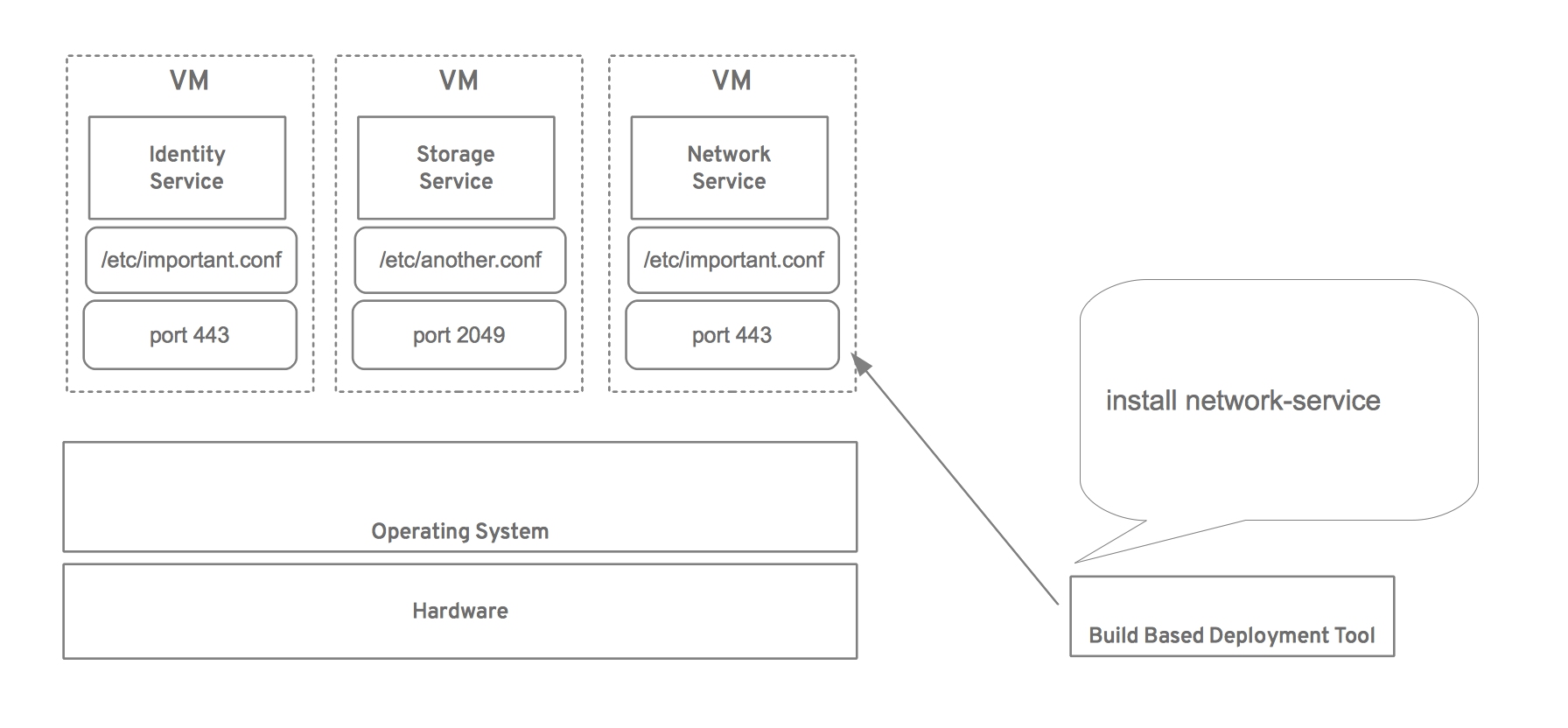
For example, let’s suppose that one wants to deploy a network service. Assuming they are using a build based (sometimes referred to as package based) deployment method they might perform something similar to the following.


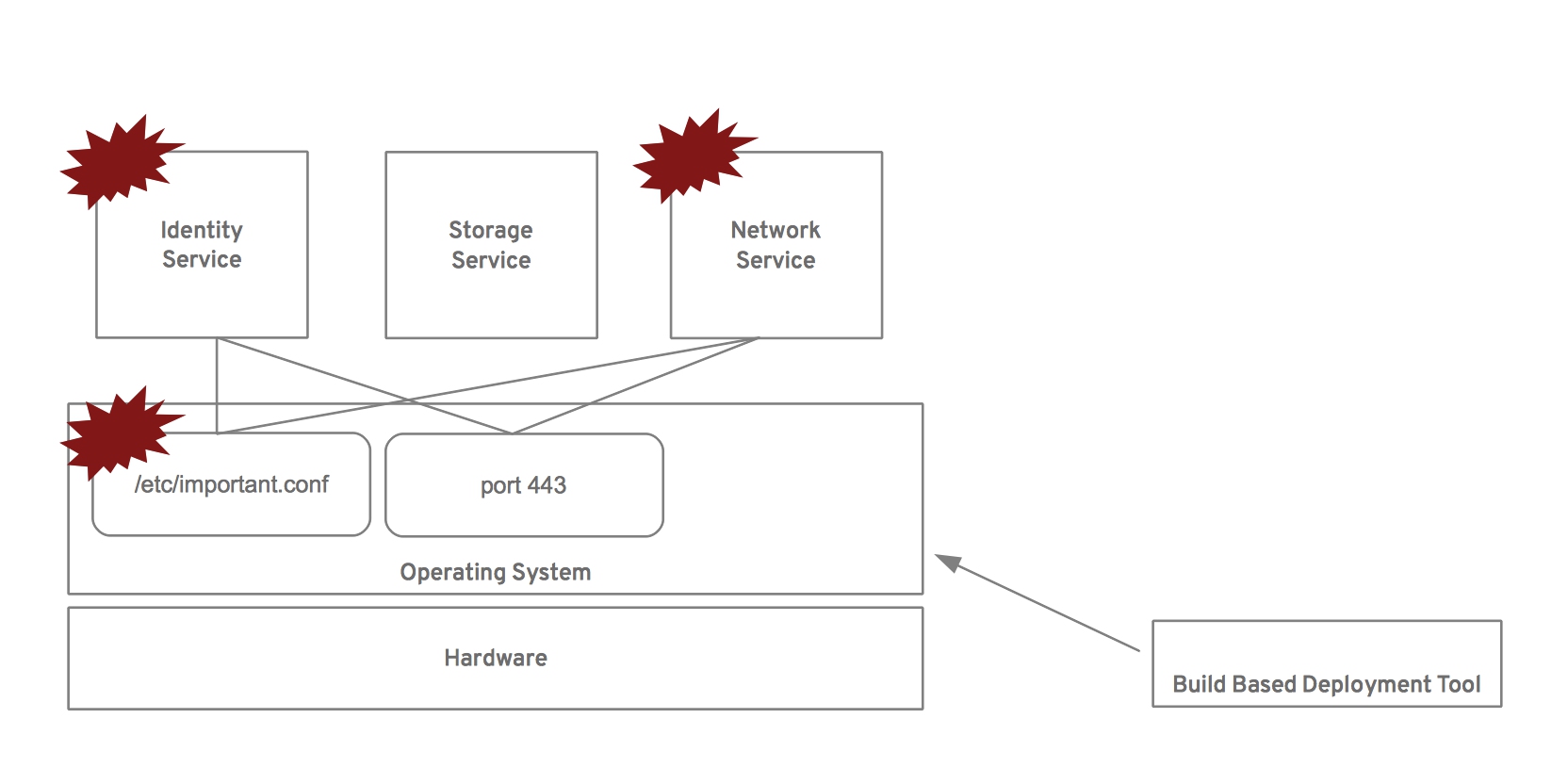
The result is a non-working network service and the potential for a non-working identity service if it is ever restarted. This problem is also found in image based deployment, it’s simply found earlier in the workflow, during the image generation phase. After all, the images that are being deployed need to be generated in the first place. The fundamental problem is that understanding what services are deployed on a particular host and resolving the dependencies or making necessary changes is not something the package or image generation tools understand.
One possible solution is to place each service on it’s own unique piece of hardware. This solves the problem of conflicts between the services configuration, but is not optimal as the overhead of the OpenStack services would not justify it’s own physical system until a particular scale is reached. Even then, locating the services close to compute nodes would also inhibit providing each service it’s own dedicated piece of hardware.
Another possible solution is to build into the tools, the logic and understanding of the OpenStack services and their configuration. While this sounds like a small task – it is not. The possible combinations of services that could be combined on a single host does not lend itself to easily creating let alone maintaining this logic.
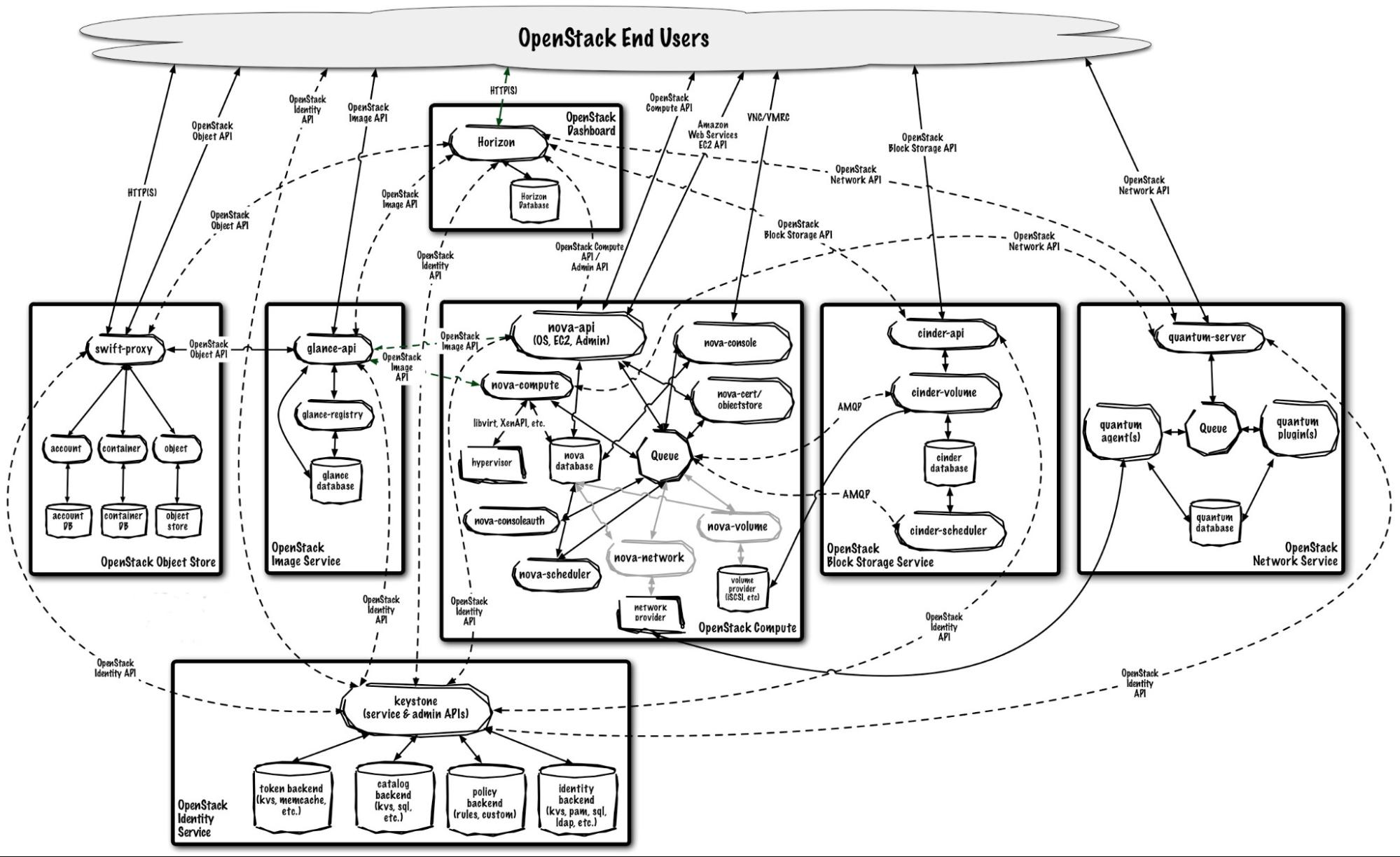
OpenStack Architecture
Yet another possible solution is to utilize virtual machines. This solves the hardware problem and provides isolation, but it has some disadvantages. Virtual machines are heavyweight. Whether it’s building new virtual machine images because of a simple update or installing the configuration infrastructure necessary to update virtual machines (and the overhead of start/stop operations, less rich interfaces for metadata, etc) virtual machines are not ideal.


It may be possible to use Linux containers to solve this problem. Linux containers offer a lightweight virtualization that provide (among other things) process and network isolation. The isolation provided by containers means that tools such as a build based or image based deployment tools don’t need to maintain the logic of how the services on hosts could be deployed or updated without effecting one another.

I hope to provide more information soon on how projects like systemd might provide a mechanism for solving dependencies between OpenStack services running in containers – maybe even using Docker. Also, how ostree might lend a hand in some of the troubles of package management too.
Building Docker Images on Fedora
This page captures my effort to learn about docker images by building a docker image for ovirt-engine from scratch using Fedora 19. At this point I get stuck after launching the image with ovirt installed in it. I’ll be troubleshooting and seeing how I can best package ovirt-engine into a single image or breaking into multiple pieces. Who knows, maybe I’ll even try to make it communicate over etcd?
I was able to create a new base image, publish it to a private docker registry, then create a Dockerfile to create a layered image for ovirt-engine, the open source virtualization management platform. I used Marek Goldmann‘s great blog as a reference and leveraged the work of Matt Miller too.
Setup your System
On a Fedora 19 system install the necessary packages.
Install docker-io docker-registry. Docker automates deployment of containerized applications while docker-registry provides the docker registry server for sharing of docker images.
# yum install -y docker-io docker-registry --enablerepo=updates-testing
Install appliance-tools. Appliance tools is one method that can be used for creating a virtual machine that we will then package up into a docker image.
# yum install -y appliance-tools libguestfs-tools
Enable and start the docker and docker-registry services.
# systemctl enable docker
# systemctl start docker
# systemctl enable docker-registry
# systemctl start docker-registry
You may also want to unmount /tmp if you are running in a VM and have limited space in /tmp.
# systemctl mask tmp.mount; reboot
Build a Base Image
In order to build a base image you need to create a virtual machine image, then pack it up into an archive, and import it into docker.
You can use your favorite kickstart file for your base docker image. You would want to make the kickstart install the smallest possible footprint so your base image stays small. The following example kickstart is a good starting point.
appliance-creator can be used to automatically install a virtual machine using the kickstart file.
# appliance-creator -c mykickstart.ks -d -v -t /tmp \
-o /tmp/myimage --name "fedora-image" --release 19 \
--format=qcow2;
virt-tar-out creates a tar file from a virtual machine image.
# virt-tar-out -a /tmp/myimage/fedora-image/fedora-image-sda.qcow2 / - |
docker import - jlabocki f19
You can download the buildcontainers.sh script and container-small-19.ks kickstart which will help you with automating the building of a basic container.
If you have issues creating a container you can continue on by pulling an existing image, like Matt’s fedora image, from the Docker index.
# docker pull mattdm/fedora
Publish the New Image to a Docker Registry
Docker provides a registry, a place to store your docker images (web server that supports multiple storage back-ends and has hooks for authentication sources). The company behind docker provides an index which is the docker-registry combined with a web front end and collaborative environment.
Now that we have a docker image we can upload it to our private registry. First you’ll need to list the images, tag the image
# docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
none latest e4a4f6d69590 29 hours ago 131.2 MB
# docker tag e4a4f6d69590 localhost.localdomain:5000/fedora-small
# docker push localhost.localdomain:5000/fedora-small
Create a New Dockerfile
Now let’s try to create a new image based on the base image. We will create a new directory and create a dockerfile.
# mkdir ovirt; cd ovirt; vi Dockerfile
A dockerfile accepts a bunch of options. We will use only a few in ours.
# Base on the Fedora image created by Matthew
FROM localhost.localdomain:5000/fedora-small
# Install the JBoss Application Server 7
#RUN yum install -y jboss-as
RUN yum localinstall -y http://ovirt.org/releases/ovirt-release-fedora.noarch.rpm
RUN yum install -y ovirt-engine
RUN yum install -y ovirt-engine-setup-plugin-allinone
RUN yum install -y wget
#RUN wget http://10.16.132.12/pub/answerfile -O /root/answerfile
# Run the JBoss AS after the container boots
# ENTRYPOINT /usr/bin/engine-setup --config=/root/answerfile
The FROM line indicates what base image should be used.
The RUN lines will be executed and committed on the image.
The ENTRYPOINT line specifies what should be executed when the image is launched. At this point I’ll leave the ENTRYPOINT commented out. We’ll just launch a shell and then try to execute the engine-setup command before we use an answerfile to install it automatically in a future image.
Now we will build our image.
# docker build .
Now we have a new image.
# docker images
We can tag this new image.
# docker tag 234ad73r7df localhost.localdomain:5000/ovirt-fedora-small
And we can push it to our registry as a new image.
# docker push localhost.localdomain:5000/ovirt-fedora-small
On another fedora 19 system with docker installed (or on the same one), you can pull the docker image down and run it.
# docker pull youripaddress:5000/ovirt-fedora-small
....
# docker run -i -t localhost.localdomain:5000/jlabocki/fedora-ovirt-small /bin/bash
You can run `docker help run` to understand the options that we just gave to run the image. You can also inspect the images and running containers to get lots of interesting information about it (from outside the container, not from within it). `docker ps a` will list the running containers while `docker images` will list the images you have.
From within the container, let’s try to run the engine-setup command and see how far we get …
bash-4.2# engine-setup
[ INFO ] Stage: Initializing
[ INFO ] Stage: Environment setup
Configuration files: ['/etc/ovirt-engine-setup.conf.d/10-packaging-aio.conf', '/etc/ovirt-engine-setup.conf.d/10-packaging.conf']
Log file: /var/log/ovirt-engine/setup/ovirt-engine-setup-20131219122235.log
Version: otopi-1.1.2 (otopi-1.1.2-1.fc19)
[ INFO ] Stage: Environment packages setup
[ INFO ] Stage: Programs detection
[ INFO ] Stage: Environment setup
[ ERROR ] Failed to execute stage 'Environment setup': Command 'initctl' is required but missing
[ INFO ] Stage: Clean up
Log file is located at /var/log/ovirt-engine/setup/ovirt-engine-setup-20131219122235.log
[ INFO ] Stage: Pre-termination
[ INFO ] Stage: Termination
[ ERROR ] Execution of setup failed
It looks like the ovirt-engine is looking for initctl, or at least that is the error it is throwing. Let’s see if we can fool the engine-setup command into thinking it exists.
# ln -s /usr/sbin/service /usr/bin/initctl
Re-running engine-setup
bash-4.2# engine-setup
[ INFO ] Stage: Initializing
[ INFO ] Stage: Environment setup
Configuration files: ['/etc/ovirt-engine-setup.conf.d/10-packaging-aio.conf', '/etc/ovirt-engine-setup.conf.d/10-packaging.conf']
Log file: /var/log/ovirt-engine/setup/ovirt-engine-setup-20131219122459.log
Version: otopi-1.1.2 (otopi-1.1.2-1.fc19)
[ INFO ] Stage: Environment packages setup
[ INFO ] Stage: Programs detection
[ INFO ] Stage: Environment setup
[ INFO ] Stage: Environment customization
Disabling all-in-one plugin because hardware supporting virtualization could not be detected. Do you want to continue setup without AIO plugin? (Yes, No) [No]: Yes
--== PACKAGES ==--
[ INFO ] Checking for product updates...
[ INFO ] No product updates found
--== ALL IN ONE CONFIGURATION ==--
--== NETWORK CONFIGURATION ==--
Host fully qualified DNS name of this server [502fbe26fc3c]:
[WARNING] Host name 502fbe26fc3c has no domain suffix
[WARNING] Failed to resolve 502fbe26fc3c using DNS, it can be resolved only locally
--== DATABASE CONFIGURATION ==--
Where is the database located? (Local, Remote) [Local]:
Setup can configure the local postgresql server automatically for the engine to run. This may conflict with existing applications.
Would you like Setup to automatically configure postgresql, or prefer to perform that manually? (Automatic, Manual) [Automatic]:
--== OVIRT ENGINE CONFIGURATION ==--
Engine admin password:
Confirm engine admin password:
[ ERROR ] Failed to execute stage 'Environment customization': [Errno 2] No such file or directory: '/usr/share/cracklib/pw_dict.pwd'
[ INFO ] Stage: Clean up
Log file is located at /var/log/ovirt-engine/setup/ovirt-engine-setup-20131219122459.log
[ INFO ] Stage: Pre-termination
[ INFO ] Stage: Termination
[ ERROR ] Execution of setup failed
Here is the output of ovirt-engine-setup-2013.log. It appears that I’m missing some files for password. It turns out the password dictionary file was missing, but it was just compressed. Let’s uncompress it and see if we can re-run engine-setup.
bash-4.2# gzip -d /usr/share/cracklib/pw_dict.pwd.gz
bash-4.2# engine-setup
[ INFO ] Stage: Initializing
[ INFO ] Stage: Environment setup
Configuration files: ['/etc/ovirt-engine-setup.conf.d/10-packaging-aio.conf', '/etc/ovirt-engine-setup.conf.d/10-packaging.conf']
Log file: /var/log/ovirt-engine/setup/ovirt-engine-setup-20131219125142.log
Version: otopi-1.1.2 (otopi-1.1.2-1.fc19)
[ INFO ] Stage: Environment packages setup
[ INFO ] Stage: Programs detection
[ INFO ] Stage: Environment setup
[ INFO ] Stage: Environment customization
Disabling all-in-one plugin because hardware supporting virtualization could not be detected. Do you want to continue setup without AIO plugin? (Yes, No) [No]: Yes
--== PACKAGES ==--
[ INFO ] Checking for product updates...
[ INFO ] No product updates found
--== ALL IN ONE CONFIGURATION ==--
--== NETWORK CONFIGURATION ==--
Host fully qualified DNS name of this server [502fbe26fc3c]:
[WARNING] Host name 502fbe26fc3c has no domain suffix
[WARNING] Failed to resolve 502fbe26fc3c using DNS, it can be resolved only locally
--== DATABASE CONFIGURATION ==--
Where is the database located? (Local, Remote) [Local]:
Setup can configure the local postgresql server automatically for the engine to run. This may conflict with existing applications.
Would you like Setup to automatically configure postgresql, or prefer to perform that manually? (Automatic, Manual) [Automatic]:
--== OVIRT ENGINE CONFIGURATION ==--
Engine admin password:
Confirm engine admin password:
[WARNING] Password is weak: it is based on a dictionary word
Use weak password? (Yes, No) [No]: Yes
Application mode (Both, Virt, Gluster) [Both]:
Default storage type: (NFS, FC, ISCSI, POSIXFS) [NFS]:
--== PKI CONFIGURATION ==--
Organization name for certificate [Test]:
--== APACHE CONFIGURATION ==--
Setup can configure the default page of the web server to present the application home page. This may conflict with existing applications.
Do you wish to set the application as the default page of the web server? (Yes, No) [Yes]:
Setup can configure apache to use SSL using a certificate issued from the internal CA.
Do you wish Setup to configure that, or prefer to perform that manually? (Automatic, Manual) [Automatic]:
--== SYSTEM CONFIGURATION ==--
--== END OF CONFIGURATION ==--
[ INFO ] Stage: Setup validation
[ ERROR ] Failed to execute stage 'Setup validation': Database configuration was requested, however, postgresql service was not found. This may happen because postgresql database is not installed on system.
[ INFO ] Stage: Clean up
Log file is located at /var/log/ovirt-engine/setup/ovirt-engine-setup-20131219125142.log
[ INFO ] Stage: Pre-termination
[ INFO ] Stage: Termination
[ ERROR ] Execution of setup failed
Conclusion
At this point the engine-setup command is not able to complete successfully because of a dbus error when trying to initialize postgresl-server. I’ll continue to work on this to see if I can make progress in packaging ovirt-engine into a docker image.
