The business environment has never been more competitive and disruptive than it is today. Businesses need to come to terms with three realities:
- They need a continuous competitive advantage
Just ask Kodak who has seen the camera business transform from a standalone device to a feature on every mobile phone with new players like Snapfish, Shutterfly, and Chatbooks creating new ways of engaging with markets. If you don’t have a way of continually developing new competitive advantages you will not be relevant for long.
- They are a software company
Bank of America is not just a bank, they are a transaction processing company. Exxon Mobil, is not only an oil and gas company, they are a GIS company. With each passing day Walgreens business is more reliant on electronic health records.
- Their competition is everywhere
Ten years ago if I asked you who the biggest competitive threats were to Fedex names like UPS, and DHL might come to mind. Increasingly Fedex, UPS, and DHL face threats from Uber, Walmart, Amazon, and others who may enter their market of logistics with new ways of reaching customers.
What do businesses need to do given these three realities?
To quote Mark Zuckerberg, they need to “Move fast and be stable”. Moving fast and being stable can be translated to more quickly developing new services that could be scaled to meet fast growing demand if needed but also with an extremely low cost of failure should they not work. In other words, cheap experiments need to be able to become global successes.
The scientists conducting these cheap experiments are software developers. Lines of business naturally turn towards their development teams to request new services at an increasingly faster rate. The problem is, developers can’t obtain those environments fast enough from operations because traditional processes and non-flexible infrastructure and applications stand in the way. It’s no surprise then, according to a 2012 McKinsey and Company study [1], that software delivery in the enterprises surveyed was 45% over budget, 7% over on time, and has 56% less value than expected when delivered.
This is no secret to businesses and they are looking to new methods and designs to help improve these metrics. In fact:
- Over 90 percent are running or experimenting with Infrastructure as a Service [2].
- Greater than 70 percent expect to use Platform as a Service in their organization [3].
- More than 90 percent expect new investments in DevOps enabling technologies in the next two years [4].
- Over 70 are using or anticipate using containers for cloud applications.
Businesses are turning to new development and operations processes, new cloud infrastructures, and application methodologies that are conducive to these new processes and infrastructures. Looking at one of the leaders in public cloud, Amazon Web Services, we see they use these same principles and designs to achieve upwards of 10,000 releases per hour (as much as a release every 12 seconds) with a very low outage rate caused by these releases.
At first glance it would appear that enterprises could simply yell “DevOps and Cloud to the Rescue!” and solve their problem of deploying faster on scalable infrastructure, but the reality is far from that. Enterprises have existing assets and investments, and many of these are not going away anytime soon. In fact, the existing systems and processes most likely power the very core of the business and cannot simply be replaced over night nor would they fit the paradigm of moving quickly and experimenting. Gartner coined the term Bi-modal to describe this approach of two modes of delivery for IT – one focused on agility and speed and the other on stability and accuracy.
Gartner has also recognized an approach that enterprises can take that would allow them to maximize the use of their existing assets. In their research “DevOps in the Bimodal Bridge” [7] they suggest an approach where the patterns and practices of DevOps can be applied to existing assets (mode 1) to make it more agile and efficient.
I have observed this trend and I believe most organizations are trying to address four key problems across their emerging bi-modal world.
In mode-1 they are looking to increase relevance and reduce complexity. In order to increase relevance they need to deliver environments for developers in minutes instead of days or weeks. In order to reduce complexity they need to implement policy driven automation to reduce the need for manual tasks.
In mode-2 they are looking to improve agility and increase scalability. In order to improve agility they need to create more agile development and operations processes and embrace new application architectures that allow for greater rates of change through decreased dependencies. In order to increase scalability they need to implement infrastructure that utilizes an asynchronous design and is entirely API driven in order to change the admin to host ratio from a linear to an exponential model in order to increase scalability.
In order to make these examples more concrete, let’s look at each of them in more detail.
Increasing Relevance by Accelerating Service Delivery
Delivering development and test environments to developers in many enterprises generally starts with either a request to a service management system or a tap on the shoulder of a system administrator. This usually depends on the size of the organization and maturity of the IT department. Either way, once requests fall into a service management system there are often many teams that need to perform tasks to deliver the environment to the developer. These might include virtual infrastructure administrators, systems administrators, and security operations. In larger organizations you could expect to see disaster recovery teams, networking teams, and many others involved in this process too. Again, depending on the maturity of the organization how all of this is coordinated could range from taps on shoulders to passing tickets around in a service management system.
At best each team takes minutes or hours to respond and perform some manual tasks and often the person who requests the service must be asked follow up questions (“Are you sure you need 16GB of RAM?”, “What version of Java do you need for this?”). The result is lots of highly skilled people spending lots of time and very slow delivery of this environment to the developer. Multiply this by the number of developers in an organization and the number of requests for environments and you can understand why traditional IT processes and systems are struggling to maintain relevance.
A solution for this problem is to introduce a service designer into the process (you may be familiar with this from ITIL) that can enable self-service consumption of everything developers need. The designer works with all stakeholders including virtual infrastructure administrators, system administrators, and security operations to obtain requirements. Then, the designer builds the necessary configuration management content and couples it with a service catalog item. By invoking this catalog item the environment can be deployed automatically across any number of providers including virtualization providers, private, or public cloud.
The result of this solution is that all the teams responsible for delivering an environment are now free to do more valuable work (like working with development to design operations processes that work as part of development instead of being bolted on after). It also removes human error from the equation, and most importantly, it delivers the environment in significantly less time. We have seen upwards of a 95 percent improvement in delivery times in many of our customers [9].
Reducing Complexity by Optimizing IT
Speeding up delivery of environments to developers or end users is a great way to make IT more relevant, but a lot of what IT is spending their time on is the day-to-day management of those environments. If IT is spending so much time on day-to-day tasks how can we expect them to deploy the next generation of scalable and programmable infrastructure or have time to work with development teams during early stages of development to increase agility?
I have found that many virtual infrastructure administrators spend time on several common tasks that should be largely automated through policy.
First, are policies around workload placement. Often one virtual infrastructure cluster will be running hot while another one is completely cold. This leads to operations teams being inundated by calls from the owners of applications running on the hot cluster asking why response times are poor. Automating this balancing through control policies can alleviate this problem and keep virtual infrastructure administrators free to other things.
Next is the ability to quickly move workloads between different infrastructures. This has become increasingly important as organizations looks to adopt scale-out IaaS clouds. Operations leadership realizes if they can identify workloads that do not need to run on (typically) more expensive virtual infrastructure they could save money by moving those workloads to their IaaS private cloud. This migration is typically a manual process and it’s also difficult to even understand what workloads can be moved. By having a systematic and automated way of identifying and migrating workloads enterprises can save time and move workloads quickly to reduce costs.
Yet another issue is ensuring compliance and governance requirements are met, particularly with workloads running on new infrastructures, like an OpenStack based private cloud. Not knowing what users, groups, data, applications, and packages reside on systems running across a heterogeneous mix of infrastructure presents a large risk and operations teams often have the responsibility and obligation of ensuring this risk is minimized. By being able to introspect workloads across platforms operations teams can gain insight into exactly what users, data, and packages are running on systems and leverage the migration capabilities I mentioned previously to make sure systems are running on appropriate providers.
Finally, since IT has often become a broker of public cloud services it’s important that they can account for costs and place workloads on appropriate regions in the public cloud to control costs while also ensuring service levels for end users are maintained. If developers are based in Singapore then we should leverage public cloud infrastructure in that location instead of deploying to a more expensive and more latent public cloud infrastructure in Tokyo.
By implementing policy based automations our customers have seen large improvements in their resource utilization and a reduction in CapEx and OpEx per workload managed [10].
Improving Agility by Modernizing Development and Operations
With resources now free from handling each and every inbound request for an environment and being confident that those environments are running efficiently and securely on the right providers operations teams can begin to work with development teams to design new processes for their cloud native applications.
These newly designed processes and cross-functional team structure combined with a platforms that supports running the broadest amount of languages and frameworks within microservices based architectures will enable the development and operations teams to achieve higher release frequencies. By utilizing microservices and standardized platforms and configurations these new applications will allow for independent release and scaling of components of the application.
This results in an increased success rate of change, faster cycle time, and the ability to scale specific services independently, making the life of both development and operations teams easier and allowing them to meet the needs of the line of business. We have experience doing this with very large software development organizations [11].
Scalability with Programmable Infrastructure
As agility of development and operations processes is improved and release frequency increased, so to does the demand for more scalable infrastructure to run those releases on. Operations teams face the challenge of delivering infrastructure that will scale to meet the demand of this ever-growing number of applications. The last thing the head of operations would like to have to explain to the management team of a company is why an extremely successful new application was hitting a wall as to the maximum number of users it could support. This simply can’t happen. Unfortunately, the current infrastructure is not scalable, neither from a financial nor technical standpoint.
One option might be to build out a scale-out infrastructure, perhaps based on OpenStack, the leading open source project for infrastructure-as-a-service. However, the operations team doesn’t want to spend it’s time taking open source code and making it consumable and sustainable for the enterprise. It doesn’t have the resources to test and certify that OpenStack will work with each new piece of hardware it brings in. It also can’t afford to maintain the code base for long periods of time with the resources available. Finally, OpenStack is missing key features that operations needs and they don’t want to develop those in house as well.
What operations really needs is a way to minimize cost and increase scale through the use of commodity hardware and a massively scalable distributed architecture coupled with the enterprise management features required to operate that infrastructure and a stable, tested, certified way of consuming the open source projects that make up that infrastructure. By having this, operations can deploy scale-out infrastructure in multiple locations and still aggregate management functions like chargeback, utilization, governance, and workflows into a single logical location. Many of our customers have found this solution beneficial in reducing cost and ensuring stability at scale [12].
Introducing Red Hat Cloud Suite
Red Hat Cloud Suite is a family of suites from Red Hat that brings together all the award winning products from Red Hat in a consistent way to solve specific problems. It allows IT to accelerate service delivery and optimize their existing assets while allowing them to build their next generation infrastructure and application platforms to support massive salability and more agile development and operations processes. In other words, it meets them where they are and lays the foundation for where they want to go.
A Different Approach
It should come as no surprise to you that Red Hat is not the only company solving these problems. Red Hat is, however, one of the few companies that can solve all of these problems because of its broad portfolio of technologies and expertise. Most think of Red Hat as having the largest percentage of the paid Linux market share. That is true, but Red Hat has been adding to its portfolio and has grown acquired expertise and industry leading technology from Software Defined Storage [13][14] to Mobile Development Platforms [15]. These offerings place Red Hat alone with only Microsoft in terms of depth of capability.
An Important Difference
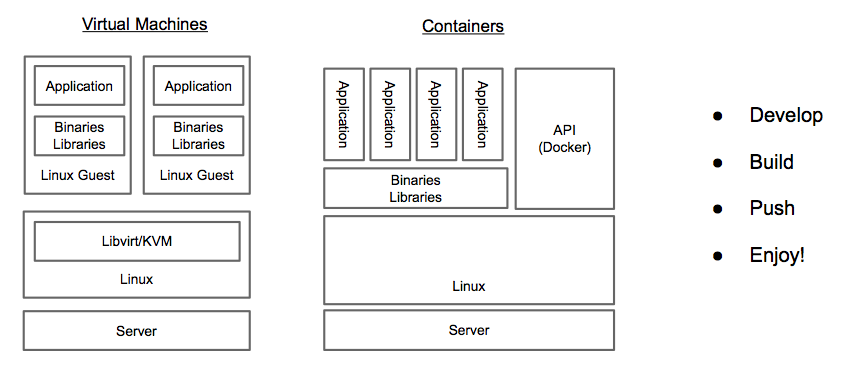
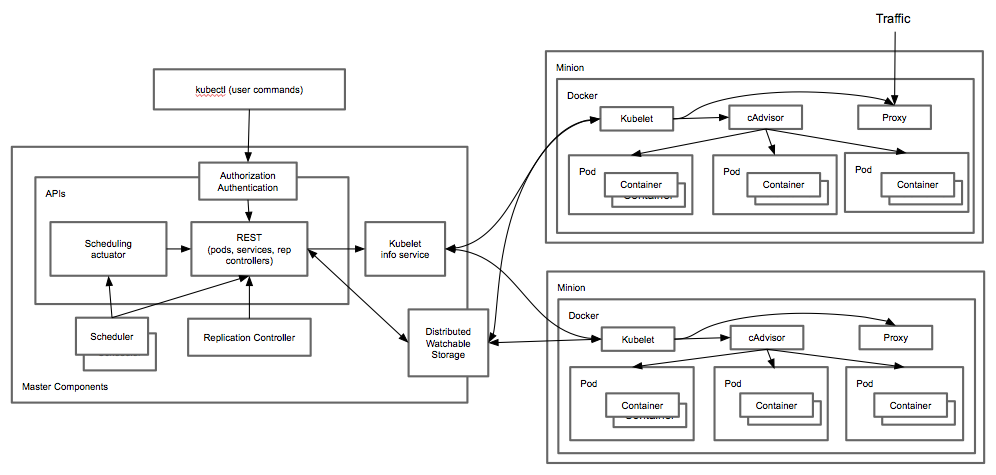
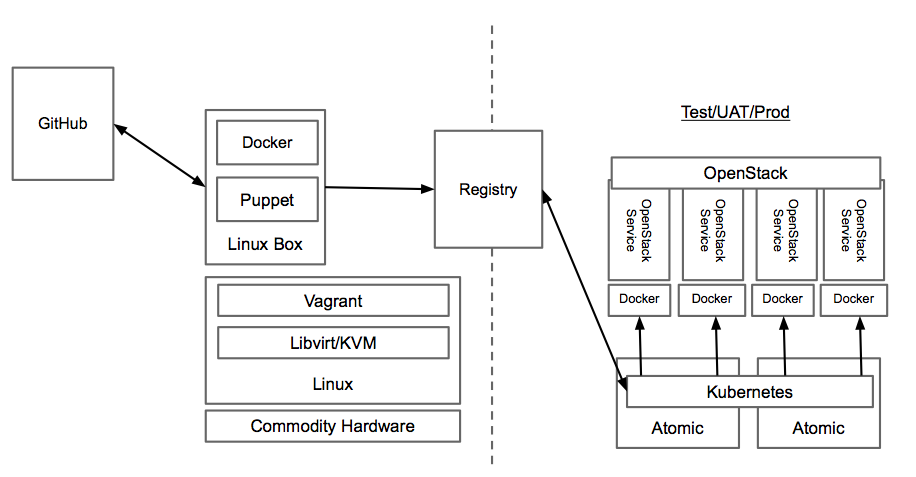
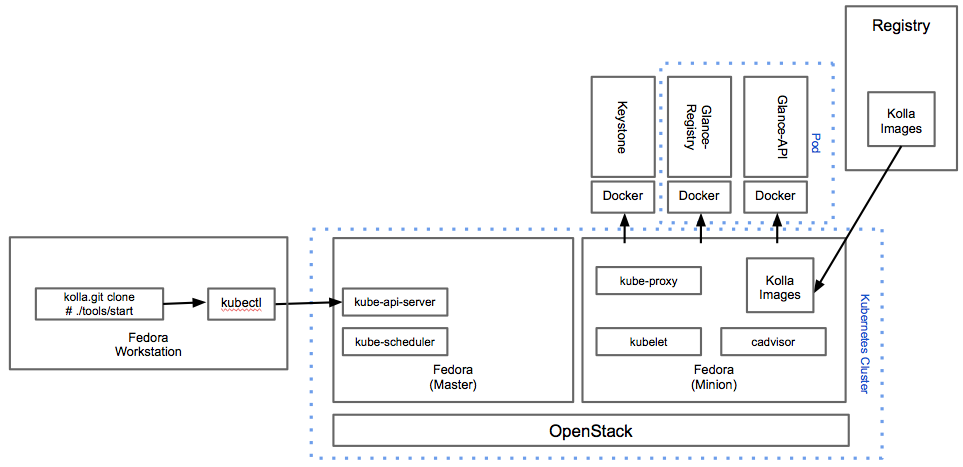
Along with this depth of expertise and capability comes an approach that sets Red Hat apart. Red Hat is the only vendor that uses an open source development model for all of the solutions it delivers. This is important for customers because the world of cloud infrastructure and applications and DevOps is built entirely on open source software. By having a strict open source only mentality customers can have access to the greatest amount of innovation and be ensured that as technologies change they could adopt them more easily because Red Hat can adopt and deliver these technologies. Two great examples of this are how Red Hat adopted the KVM hypervisor [16] and embraced and delivered it’s container platform with support for Docker and Kubernetes [17] – leading open source projects that become popular in a short amount of time. Red Hat is committed to the open source development model, so much so that it even creates communities when it acquires non-open source licensed technologies [18]. Customers should know that when they leverage a solution from Red Hat it is based entirely on open source, leading to greater access to innovation and lower exit costs.
Technical Capabilities are Important Too
While philosophical differences are important for ensuring that the right long term decisions have been made, Red Hat is also at the forefront of innovation in cloud infrastructure, applications, and DevOps tools.
True Hybrid Support
The term hybrid cloud has often been over used and abused, but it is important. Enterprises need to be able to run workloads across the four major deployment models that exist today: physical, virtual, private, and public cloud. Equally as important to the deployment model is the ability to support multiple service models, such infrastructure-as-a-service, platform-as-a-service, or even bare metal, virtual machines running on scale-up virtual infrastructure, and public cloud services. When most vendors claim they support “hybrid” cloud they are typically limited to only managing hybrid deployment models. Red Hat supports both hybrid deployment models and hybrid service models. This is important to both Development and Operations teams. For developers, it means being able to develop on the broadest choice of languages and frameworks. They could use an Oracle database running on bare-metal or virtual machine, JBoss EAP running on virtual machines on OpenStack, combined with Node.js and Ruby running in Containers on OpenShift. They are not constrained to a single service model that doesn’t give them everything they need.
Using Big Data to Optimize IT
Red Hat has been supporting Linux for a long time. In fact, we’ve been supporting Red Hat Enterprise Linux for over 13 years since RHEL AS 2.1’s release in 2002 [16]. There are over 700 Red Hat Certified Engineers in our support organization and they’ve documented over 30,000 solutions while resolving over 1 million technical issues. The Red Hat customer portal has won plenty of awards for helping connect customers searching for resolution to an issue to the right technical solution. With Red Hat Access Insights, Red Hat’s new predictive analytics service, connecting support data to recommendations is going to reach a new level of ease of use. Users can send small amounts of data about their environment back to Red Hat and it will be compared to optimal configurations to find opportunities to improve security, reliability, availability, and performance. This service is already available for Red Hat Enterprise Linux and will soon be available for all the technologies in Red Hat’s portfolio through Red Hat Cloud Suite.
An Easy On-ramp and Consistent Lifecycle
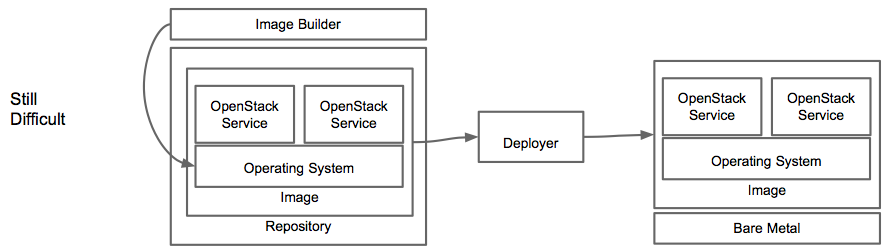
Deploying a private cloud is not an easy task. The list of platforms that need to come together from configuration management, to storage, to infrastructure-as-a-service, to platform-as-a-service is large. Each of these has dependencies on sub-components within each of these platforms. For example, to generate new docker images need secure content and that takes integration between the content management system and the image building services. Literally hundreds of these integrations are needed to build a fully functional private cloud. This usually results in one of two options:
- Operations requiring lots and lots of time to deliver this private cloud.
- An army of high priced consultants arriving to deliver and maintain a private cloud.
Neither of these options are an optimal results for IT. Red Hat Cloud Suite provides an easy on-ramp that allows a single person in operations to deploy a private cloud and it provides the path for ongoing management of that private cloud. This allows developers to begin using the private cloud more quickly and helps operations deliver a private cloud more quickly.
A Quick Summary
Here is a quick summary for those that just want the cliff notes.
The World is Changing
- Businesses need a continuous competitive advantage
- All businesses are software companies
- Competition is everywhere
IT Needs
- To increase relevance and reduce complexity
- To create more agile processes and build programmable & scalable infrastructure and platforms
Red Hat Helps
- Accelerate delivery
- Optimize for efficiency
- Modernize development and operations
- Deliver scalable infrastructure
Only Red Hat Delivers
- Innovation in the form of pure open source solutions
- Integration with world class testing, support, and certification
References
[1] http://www.mckinsey.com/insights/business_technology/delivering_large-scale_it_projects_on_time_on_budget_and_on_value
[2] http://www.forbes.com/sites/benkepes/2015/03/04/new-stats-from-the-state-of-cloud-report/
[3] http://www.forbes.com/sites/louiscolumbus/2013/06/19/north-bridge-venture-partners-future-of-cloud-computing-survey-saas-still-the-dominant-cloud-platform/
[4] DevOps, Open Source, and Business Agility. Lessons Learned from Early Adopters. An IDC InfoBrief, sponsored by Red Hat | June 2015
[5] http://www.redhat.com/cms/public/RH_dev_containers_infographic_v1_0430clean_web.pdf
[6] https://puppetlabs.com/2014-devops-report
[7] https://www.gartner.com/doc/3022020/devops-bimodal-bridge
[8] http://www.gartner.com/it-glossary/bimodal
[9] http://www.redhat.com/en/resources/union-bank-migrates-unix-and-websphere-red-hat-and-jboss-solutions
http://www.redhat.com/en/resources/g-able-improves-resource-allocation-red-hat-solutions
[10] http://www.redhat.com/en/resources/cbts-enhances-customer-service-red-hat-cloudforms
[11] www.openshift.com/customers
[12] http://www.redhat.com/en/resources/morphlabs-reinvents-cloud-services-enterprise-ready-iaas-solution
[13] http://www.redhat.com/en/about/press-releases/red-hat-acquire-inktank-provider-ceph
[14] http://www.redhat.com/en/about/blog/red-hat-to-acquire-gluster
[15] http://www.redhat.com/en/about/press-releases/red-hat-acquire-feedhenry-adds-enterprise-mobile-application-platform
[16] http://www.infoworld.com/article/2627019/server-virtualization/red-hat-drops-xen-in-favor-of-kvm-in-rhel-6.html
[17] https://blog.openshift.com/openshift-v3-platform-combines-docker-kubernetes-atomic-and-more/
[18] https://access.redhat.com/articles/3078

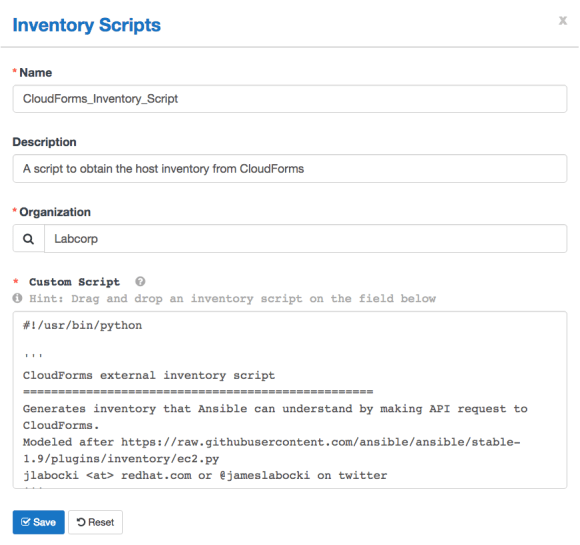
 From there select the icon to add a new inventory script. You can now add the inventory script and name it and associate it with your organization.
From there select the icon to add a new inventory script. You can now add the inventory script and name it and associate it with your organization.